DNS 서비스에서 가장 중요한 것은 분산 네트워크 서비스의 형태를 지원하는 것이다.
인터넷에서 네임 서버는 여러 곳에 흩어져 있다. 이들 서버는 전체 네임스페이스의 일부 정보를 전적으로 책임지며, 유기적인 연관 관계를 통해 네임 서버의 정보를 일관성 있게 관리한다.
해석기
DNS 서비스는 클라이언트-서버 구조로 설계되었다. 도메인 이름과 호스트 주소의 변환 정보를 원하는 네트워크 응용 프로그램은 해석기(Reslover)라 불리는 DNS 클라이언트에 정보 제공을 요청한다. 해석기는 가장 가까운 네임 서버와 접촉해 정보 제공을 요청하고 해당 서버에 정보가 없으면 다른 네임 서버와 접촉해 정보를 찾는 과정을 반복한다.
ex) 도메인 이름 www.korea.co.kr과 관련된 IP 주소를 얻는 과정은 해석기로부터 시작된다. 해석기가 도메인 정보를 요청할 때 먼저 질의를 생성하고, 이 질의는 DNS 메시지 형태로 구성되어 네임 서버에 전달된다. 요청을 받은 네임 서버는 결과를 회신용 DNS 메시지에 기록하여 해석기에 보낸다.
인증 데이터
네트워크에 존재하는 네임 서버가 하나면 이 서버가 DNS에 관한 모든 정보를 관리한다. 따라서 모든 해석기는 이 네임서버에 질의를 요청하고 결과를 돌려 받는다. 그러나 네트워크가 커지면서 처리 속도를 비롯해 여러 문제가 발생할 수 있어 다수의 네임 서버를 지원하며 도메인 데이터에 대해 인증 데이터와 캐시 데이터라는 두 가지 개념을 사용한다.
- 인증 데이터(Authoritative Data)는 해당 데이터를 직접 관리할 책임이 있는 네임 서버로부터 받은 정보의 의미를 의미한다.
- 캐시 데이터(Cached Data)는 이전 요청에 의해 호스트가 보관하던 데이터이며, 재사용할 목적으로 한동안 저장한다. 인터넷으로 인증 데이터는 현재의 네트워크 상태를 그댈 반영한 정확한 데이터이지만, 인터넷의 안정도를 감안할 때, 캐시 데이터를 사용해도 크게 문제되지 않는다.
서버가 캐시 데이터를 너무 오래 보관하면 클라이언트에 현재의 인증 데이터와는 다른 정보를 전달할 염려가 있다. 이를 해결하기 위해 해당 정보의 인증 서버가 TTL이라는 추가 정보를 제공한다. TTL이 초과된 정보는 자동으로 무효 처리되므로, 인증 서버에 다시 정보를 요청해서 캐시 데이터를 생신해야 한다.
존
인증 데이터는 네임 스페이스의 특정 영역인 존(Zone)을 관리하는 네임 서버가 유지하고 관리한다.
존은 자원 레코드에 포함되는 인증 데이텅의 집합체로 정의되며 아래 영역을 포함한다.
- 존세 속하는 모든 호스트의 전체 자원 레코드의 집합체
- 존에 포함된 최상위 호스트 : ex) mit, edu 존은 최상위 노드가 mit.edu이다
- 위임 서브 존 (Sub-Zone) : 자신의 존에 속하지만, 인증이 위임된 경우이다. ex) mit, edu 존 아래에 위치한 서브 존info.mit.edu의 인증이 info,mit.edu를 관리하는 담당자에게 위임된 경우이다.
- 위임된 서브 존에 관한 글루(Glue) 데이터 : 서브 존의 네임서버에 접근할 수 있도록 해준다.
임의의 네임 서버는 다른 네임 서버로부터 수신한 캐시 데이터를 유지하기 때문에 자신이 관리하는 네임 스페이스 뿐 아니라 자신의 관리 밖에 있는 호스트의 정보도 인증해줄 수 있다. 따라서 존을 적절히 관리하는 것은 매우 중요하다.

해석기가 info.mit.edu 밑에 위치한 test.info.mit.edu 호스트의 정보를 알고싶다고 가정하면, 먼저 mit.edu의 정보를 얻고, 네임 서버의 응답을 통해 다른 네임 서버가 info.mit.edu 도메인을 관리하고 있음을 알게 된다. 그리고 info.mit.edu를 관리하는 네임 서버의 IP 주소를 얻을 수 있으면 이후의 처리 과정은 일반적인 방식으로 이루어진다.
만일 서브존 info.mit.edu의 네임 서버가 서브 존 도메인 내부에 위치하면 해석기에 혼란을 줄 수 있따. 즉, mit.edu 도메인 네임 서버인 dns.mit.edu가 해석기에게 dns.info.mit.edu에 주소를 문의하라고 응답하는데, 이 때 해석기는 dns.info.mit.edu의 주소를 찾을 수 있는 방법을 강구해야 한다. 이를 해결하려고 서브 존의 위임에 관련된 글루 데이터가 사용된다. 상위 존의 네임 서버는 위임된 서브 존의 네임 서버에 관한 도메인 이름과 주소를 유지한다. 그러므로 해석기가 상위 존을 관리하는 네임 서버에 문의하여 서브 존의 네임 서버에 관한 정보를 얻는다.
요청의 처리
도메인 네임 스페이스는 서로 다른 여러 존으로 구성된 거대한 연결고리로 생각할 수 있다. 각 존을 관장하는 네임 서버는 유기적으로 협력하면서 DNS 질의 요청에 응답한다. 로컬 도메인의 인증 데이터를 가지고 있으므로 간단히 처리된다.
하지만 도메인이 다른 호스트의 정보를 요청하면 가장 관련있는 인근 네임 서버와 정보를 요청하는 호스트를 연결해야 한다. 즉, 로컬 네임 서버에 요청자가 원하는 정보가 없으면 가장 적합한 네임 서버를 선택하여 해당 서버와 접촉하도록 해주어야 한다.
가장 적절한 인근 네임 서버는 질의를 받은 네임 서버가 관장하는 존의 상위에 위치하는데, 이러한 동작은 해석기가 원하는 인증 정보를 찾을 때까지 연속적으로 반복된다. 질의 요청이 처리되는 과정은 두 가지로 나누어 생각할 수 있다.
- 호스트가 DNS 정보를 요청할 때는 인증 데이터의 필요 여부를 명시할 수 있다. 인증 데이터가 반드시 필요한 경우가 아니라면 로컬 네임 서버에 보관된 캐시 데이터를 사용할 수 도 있다.
- 해석기는 질의 요청이 재귀적으로 처리되는지 명시할 수 있다. 재귀적이라는 뜻은 햇헉기가 최초로 접촉을 시도한 네임 서버가 질의 요청을 계속 추적, 관리하면서 요청에 대해 인증 데이터를 회신하는 것이다. 네임 서버가 비재귀적인 요청을 받은 경우는 두 가지 응답이 가능한데, 자신이 인증 데이터를 가지고 있으면 이를 회신하고, 그렇지 않으면 다른 네임 서벙의 포인터 정보를 자신이 회신한다.
재귀적 처리
재귀적 요청을 받은 네임 서버는 결과적으로 해석기와 같은 역할을 수행한다. 즉, 최초의 해석기가 자신에게 요청한 것과 동일한 질의 요청을 다른 네임 서버에 전송해 원하는 결과를 찾는 과정을 반복한다.
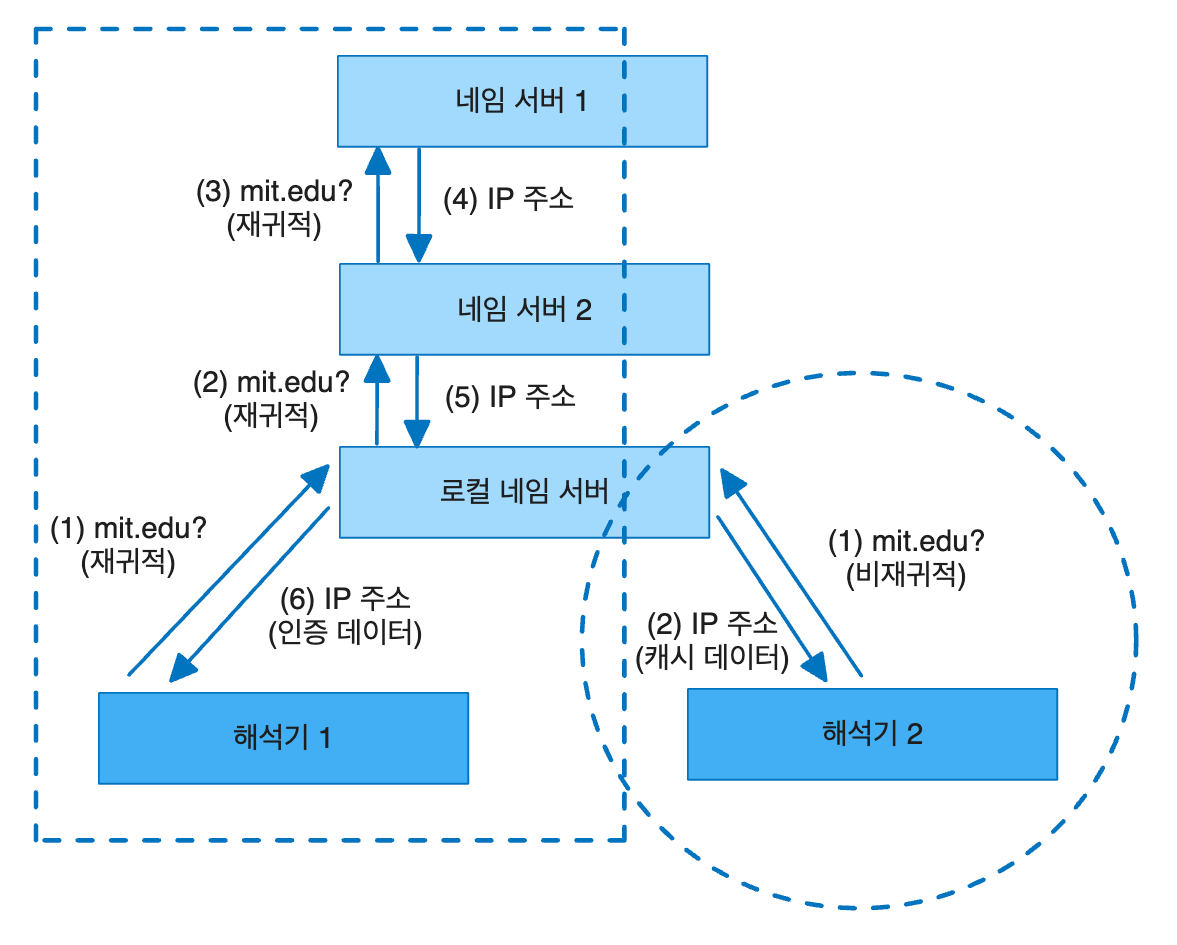
왼쪽 부분에서는 해석기 1로부터 mit.edu의 정보를 요청받은 로컬 네임 서버가 해당 호스트의 인증 번호를 보관하고 있는 네임 서버 1과 재귀적으로 접촉하여 mit.edu의 IP주소를 얻은 후에 회신하고 있다. 반면 오른쪽 부분에서는 비재귀적인 요청에 대하여 로컬 네임 서버가 보관하고 있는 mit.edu의 캐시 정보를 회신하고 있다.
반복적 처리
재귀적인 처리가 아닌 반복적인(Iterative)처리인 경우 로컬 네임 서버가 여러 네임 서버를 직접 접촉해야 한다. 즉, 네임 서버2로부터 원하는 정보를 얻지 못한 로컬 네임 서버는 네임 서버 1과 직접 접촉하여 정보를 얻어야 한다. 이때 네임 서버 1의 포인터인 IP 주소는 네임 서버 2가 제공한다.
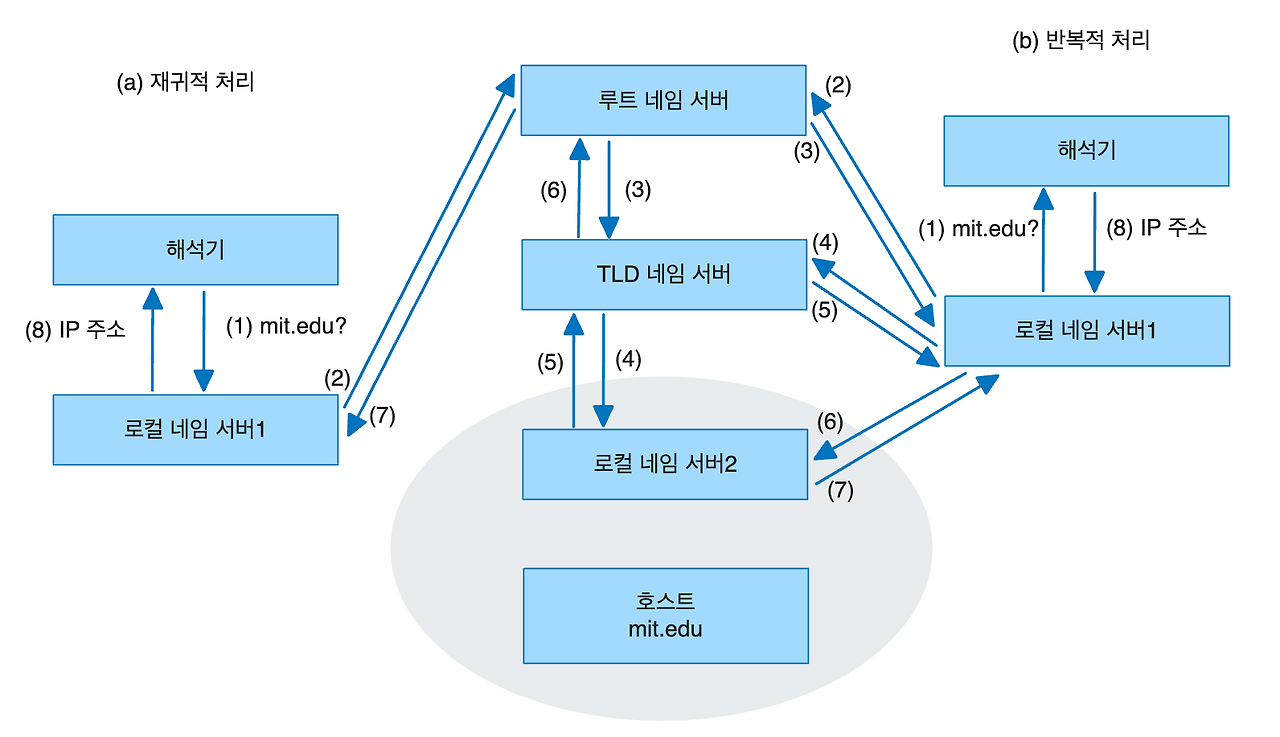
a의 재귀적 처리는 정보를 요청받은 로컬 네임 서버 1로부터 해당 호스트의 정보를 관리하는 로컬 네임 서버 2까지의 과정이 재귀적으로 이루어진다. 그에 비해 b는 로컬 네임 서버 1이 여러 네임 서버와 직접 접촉하여 원하는 정보를 얻고 있다.
Reference
쉽게 배우는 데이터 통신과 컴퓨터 네트워크
https://soso-hyeon.tistory.com/112
[쉽게 배우는 데이터 통신과 네트워크] CH14. DNS
01 DNS(Domain Name System) 서비스인터넷의 규모가 커지면서 호스트 파일을 수작업으로 관리할 수 없게 되었고, 이를 계기로 DNS 서비스가 탄생하게 되었다. 1 IP 주소 체계인터넷에서는 32비트의 이진
soso-hyeon.tistory.com
'CS > Network' 카테고리의 다른 글
| [Chapter 15] 전자 메일 (메일 처리) (0) | 2025.02.19 |
|---|---|
| [Chapter 14] DNS (DNS 프로토콜) (0) | 2025.02.18 |
| [Chapter 14] DNS (도메인 네임 스페이스) (0) | 2025.02.18 |
| [Chapter 14] DNS (DNS 서비스) (0) | 2025.02.18 |
| [Chapter 13] 웹 WWW(CGI) (0) | 2025.02.18 |