System.String
문자열 처리는 대부분 string 타입에서 제공된다.
자주 사용되는 string 타입의 멤버
| 멤버 | 유형 | 설명 |
| Contains | 인스턴스 메서드 | 인자로 전달된 문자열을 포함하고 있는지 여부를 true/false로 반환 |
| EndsWith | 인스턴스 메서드 | 인자로 전달된 문자열로 끝나는지 여부를 true/false로 반환 |
| Format | 정적 메서드 | 형식에 맞는 문자열을 생성해 반환 |
| GetHashCode | 인스턴스 메서드 | 문자열의 해시값을 반환 |
| IndexOf | 인스턴스 메서드 | 문자 또는 문자열을 포함하는 경우 그 위치를 반환하고 없으면 -1을 반환 |
| Split | 인스턴스 메서드 | 주어진 문자 또는 문자열을 구분자로 나눈 문자열의 배열을 반환 |
| StartsWith | 인스턴스 메서드 | 인자로 전달된 문자열로 시작하는지 여부를 true/.false로 반환 |
| Substring | 인스턴스 메서드 | 시작과 길이에 해당하는 만큼의 문자열을 반환 |
| ToLower | 인스턴스 메서드 | 문자열을 소문자로 변환해서 반환 |
| ToUpper | 인스턴스 메서드 | 문자열을 대문자로 변환해서 반환 |
| Trim | 인스턴스 메서드 | 문자열의 앞뒤에 주어진 문자가 있는 경우 삭제한 문자열을 반환, 문자가 지정되지 않으면 기본적으로 공백 문자를 제거해서 반환 |
| Length | 인스턴스 속성 | 문자열의 길이를 정수로 반환 |
| != | 정적 연산자 | 문자열이 같지 않다면 true를 반환 |
| == | 정적 연산자 | 문자열이 같다면 true를 반환 |
| 인덱서[] | 인스턴스 속성 | 주어진 정수 위치에 해당하는 문자를 반환 |
using System;
class Program
{
static void Main()
{
string text = "Hello World";
// Contains : 문자열 포함 여부
Console.WriteLine(text.Contains("World")); // true
// EndsWith : 특정 문자열로 끝나는지 확인
Console.WriteLine(text.EndsWith("World")); // true
// Format : 형식에 맞는 문자열 생성
string name = "Adel";
int level = 10;
string result = string.Format("Name: {0}, Level: {1}", name, level);
Console.WriteLine(result);
// GetHashCode : 문자열 해시값 반환
Console.WriteLine(text.GetHashCode());
// IndexOf : 문자 또는 문자열 위치 반환
Console.WriteLine(text.IndexOf("World")); // 6
// Split : 구분자로 문자열 분리
string fruits = "apple,banana,orange";
string[] arr = fruits.Split(',');
Console.WriteLine(arr[0]); // apple
// StartsWith : 특정 문자열로 시작하는지 확인
Console.WriteLine(text.StartsWith("Hello")); // true
// Substring : 문자열 일부 추출
Console.WriteLine(text.Substring(0, 5)); // Hello
// ToLower : 소문자 변환
Console.WriteLine(text.ToLower()); // hello world
// ToUpper : 대문자 변환
Console.WriteLine(text.ToUpper()); // HELLO WORLD
// Trim : 앞뒤 공백 제거
string spaceText = " CSharp ";
Console.WriteLine(spaceText.Trim()); // "CSharp"
// Length : 문자열 길이
Console.WriteLine(text.Length); // 11
// == : 문자열 비교
Console.WriteLine(text == "Hello World"); // true
// != : 문자열 비교
Console.WriteLine(text != "Hello"); // true
// 인덱서[] : 특정 위치 문자 접근
Console.WriteLine(text[0]); // H
}
}영문자를 다룰 때 빠질 수 없는 요소 중 하나가 바로 대소문자 구분(case sensitivity) 이다.
EndsWith, IndexOf, StartsWith와 같은 일부 문자열 메서드는 대소문자 비교 방식을 지정할 수 있는 오버로드 버전을 제공한다.
이 메서드들은 추가로 StringComparison 열거형 값을 인자로 받을 수 있다.
만약 이 인자를 생략하면 기본적으로 대소문자를 구분하는 비교가 수행된다.
반대로 대소문자를 구분하지 않고 비교하고 싶다면 StringComparison.OrdinalIgnoreCase 값을 함께 전달하면 된다.
string text = "HelloWorld";
// 기본 비교 (대소문자 구분)
Console.WriteLine(text.StartsWith("hello")); // false
// 대소문자 무시 비교
Console.WriteLine(text.StartsWith("hello", StringComparison.OrdinalIgnoreCase)); // true문자열의 == 비교 연산자는 기본적으로 대소문자를 구분하는 비교를 수행한다. 또한 Equals 메서드 역시 기본적으로는 대소문자를 구분한다.
하지만 Equals 메서드는 오버로드 버전을 제공하기 때문에 StringComparison 열거형 값을 함께 전달하면 대소문자를 무시하는 비교를 수행할 수 있다.
예를 들어 StringComparison.OrdinalIgnoreCase를 사용하면 대소문자를 구분하지 않고 문자열을 비교할 수 있다.
string a = "Hello";
string b = "hello";
// == 비교 (대소문자 구분)
Console.WriteLine(a == b);
// false
// Equals 기본 비교 (대소문자 구분)
Console.WriteLine(a.Equals(b));
// false
// Equals + 대소문자 무시
Console.WriteLine(a.Equals(b, StringComparison.OrdinalIgnoreCase));
// truestring.Format을 사용할 때는 단순히 값을 전달하는 것뿐만 아니라, 문자열을 어떤 형식으로 출력할 것인지에 대한 형식 문자열(format string)을 함께 지정해야 한다.
string name = "Adele";
int score = 95;
string result = string.Format("이름: {0}, 점수: {1}", name, score);
Console.WriteLine(result);{0}, {1}과 같은 표현을 자리 표시자(placeholder) 라고 하며, string.Format에 전달된 인자의 순서에 따라 값이 치환된다.
형식 문자열을 적용하려면 타입에서 제공되는 형식 문자열을 미리 알고 있어야 한다.
| 타입 | 유형 | 의미 | Format 예제 | 한글 윈도우 출력 |
| 숫자형 | C | 통화 | string.Format("{0:C}", -123) | -₩123 |
| D | 10진수 | string.Format("{0:D}", 123) | 123 | |
| E | 공학(지수) | string.Format("{0:E}", 123) | 1.230000E+002 | |
| F | 고정 소수점 | string.Format("{0:F}", 123.456) | 123.46 | |
| G | 일반(기본값) | string.Format("{0:G}", 123.456) | 123.456 | |
| N | 숫자(천단위 구분) | string.Format("{0:N}", 1234567) | 1,234,567.00 | |
| P | 백분율 | string.Format("{0:P}", 0.25) | 25.00 % | |
| R | 반올림 숫자 | string.Format("{0:R}", 123.456) | 123.456 | |
| X | 16진수 | string.Format("{0:X}", 255) | FF | |
| 날짜형 | Date Time now = DateTime.Now | |||
| d | 단축 날짜 | string.Format("{0:d}", now) | 2026-03-06 | |
| D | 상세 날짜 | string.Format("{0:D}", now) | 2026년 3월 6일 금요일 | |
| t | 단축 시간 | string.Format("{0:t}", now) | 오전 10:25 | |
| T | 상세 시간 | string.Format("{0:T}", now) | 오전 10:25:30 | |
| f | 전체날짜/단축시간 | string.Format("{0:f}", now) | 2026년 3월 6일 금요일 오전 10:25 | |
| F | 전체날짜/상세시간 | string.Format("{0:F}", now) | 2026년 3월 6일 금요일 오전 10:25:30 | |
| g | 일반날짜/단축시간 | string.Format("{0:g}", now) | 2026-03-06 오전 10:25 | |
| G | 일반날짜/상세시간 | string.Format("{0:G}", now) | 2026-03-06 오전 10:25:30 | |
| M | 달 | string.Format("{0:M}", now) | 3월 6일 | |
| Y | 년 | string.Format("{0:Y}", now) | 2026년 3월 | |
System.Text.StringBuilder
문자열을 다루다 보면 항상 함께 설명되는 클래스가 바로 StringBuilder이다.
C#의 string 타입은 불변 객체(immutable object) 이다.
즉, 한 번 생성된 문자열은 내부 값이 변경되지 않는다.
그래서 문자열을 수정하는 것처럼 보이는 코드도 실제로는 기존 문자열을 변경하는 것이 아니라 새로운 문자열 객체를 생성하는 방식으로 동작한다.
string text = "Hello";
text += " World";겉보기에는 "Hello" 문자열에 " World"가 추가된 것처럼 보이지만, 실제로는 "Hello World"라는 새로운 문자열 객체가 생성되고 기존 문자열은 그대로 남게 된다.
이러한 동작은 문자열을 한두 번 수정할 때는 큰 문제가 되지 않는다. 하지만 반복문 등에서 문자열을 계속 이어 붙이게 되면 매번 새로운 문자열 객체가 생성되면서 메모리 할당과 복사가 반복적으로 발생하게 된다.
string result = "";
for(int i = 0; i < 1000; i++)
{
result += i;
}이 경우 문자열이 계속 새로 생성되기 때문에 성능 저하가 발생할 수 있다. 이러한 문제를 해결하기 위해 제공되는 클래스가 바로 StringBuilder이다.
StringBuilder는 문자열을 수정할 때 기존 메모리를 재사용하면서 내부 버퍼를 변경하는 방식으로 동작하기 때문에 문자열을 여러 번 수정하는 상황에서 훨씬 효율적이다.
using System.Text;
StringBuilder sb = new StringBuilder();
for(int i = 0; i < 1000; i++)
{
sb.Append(i);
}
string result = sb.ToString();- string → 불변 객체 (수정 시 새로운 문자열 생성)
- StringBuilder → 내부 버퍼를 변경하며 문자열을 효율적으로 수정
문자열을 몇 번만 수정하는 경우에는 string을 사용해도 문제가 없지만, 반복문이나 대량의 문자열 결합이 발생하는 경우에는 StringBuilder를 사용하는 것이 성능 측면에서 더 효율적이다.
System.TextEncoding
문자와 숫자의 관계
컴퓨터는 내부적으로 모든 데이터를 숫자 형태로 처리한다.
따라서 우리가 화면에서 보는 'A', 'B', 'C' 같은 문자는 실제로는 문자가 아니라 숫자 값으로 저장되어 있다.
화면에 보이는 문자는 시스템에 내장된 폰트(font) 를 기반으로 출력되는 일종의 그림에 가깝다.
컴퓨터 내부에서는 해당 문자에 대응하는 숫자를 저장하고, 화면에 출력할 때 그 숫자에 맞는 글자를 폰트에서 찾아 보여주는 방식이다.
이처럼 문자를 특정 숫자 값과 대응시키는 규칙을 문자 코드(Character Code) 또는 문자 인코딩(Character Encoding) 이라고 한다.
예를 들어 가장 대표적인 문자 코드 체계 중 하나가 ASCII(American Standard Code for Information Interchange) 이다.
ASCII에서는 다음과 같이 문자에 숫자를 대응시킨다.
A → 65
B → 66
C → 67즉, 프로그램에서 'A'라는 문자를 사용하면 실제로는 숫자 65가 저장되고 처리되는 것이다. 이러한 문자 코드 덕분에 컴퓨터는 문자 데이터를 숫자로 처리하고 저장할 수 있게 된다.
문자 코드와 인코딩
초기의 ASCII 코드는 7비트(0~127) 만 사용했기 때문에
알파벳 대소문자, 숫자, 일부 통신용 제어 코드를 표현하는 수준에서 정의되었다.
하지만 7비트 ASCII 코드만으로는 한글, 한자, 일본어와 같은 다양한 언어를 표현할 수 없었다.
이 때문에 세계 각국에서는 자국의 문자를 표현하기 위해 ASCII를 확장한 다양한 문자 코드 체계를 만들기 시작했다.
한글 역시 이러한 과정에서 여러 인코딩 방식이 등장했다.
대표적인 예는 다음과 같다.
- EUC-KR
- CP949
- KS C 5601-1987
이처럼 국가와 환경마다 서로 다른 문자 체계를 사용하다 보니 문자 데이터를 교환할 때 호환성 문제가 발생하기 시작했다.
이 문제를 해결하기 위해 등장한 것이 유니코드(Unicode) 라는 산업 표준이다.
유니코드는 전 세계의 문자를 하나의 통합된 코드 체계로 정의한 것이다. 하지만 유니코드는 문자에 번호를 부여하는 표준일 뿐, 실제 데이터를 저장하는 방식은 여러 가지가 존재한다.
이러한 저장 방식을 부호화 방식(Encoding) 이라고 한다.
대표적인 유니코드 인코딩 방식은 다음과 같다.
- UTF-8
- UTF-16
- UTF-32
이처럼 복잡한 문자 인코딩을 쉽게 사용할 수 있도록 .NET의 BCL에서는 Encoding 타입(System.Text.Encoding) 을 제공한다.
개발자는 Encoding 클래스를 사용해 문자열과 바이트 배열 사이를 쉽게 변환할 수 있다.
using System.Text;
string text = "Hello";
// 문자열 -> 바이트 배열
byte[] bytes = Encoding.UTF8.GetBytes(text);
// 바이트 배열 -> 문자열
string result = Encoding.UTF8.GetString(bytes);
Console.WriteLine(result);
// ex) 자바와 C# 간의 문자열 교환을 UTF-8 인코딩으로 합의했다고 가정하면 UTF-8로 변환/복원하는 과정을 거쳐야 한다.
byte[] buf = Encoding.UTF8.GetBytes(textData);
//생략: buf 바이트 배열을 자바 프로그램에 전달
byte[] recived = ...; //생략: 자바 프로그램으로부터 전달받은 바이트 배열 데이터
string data = Encoding.UTF8.GetString(recived);
자주 사용되는 Encoding 유형
| 정적 속성 | 설명 |
| ASCII | 7비트 ASCII 문자셋을 위한 인코딩 |
| Default | 시스템 기본 문자셋을 위한 인코딩 (한글 윈도우의 경우 ks_c 5601-1987, 영문 윈도우의 경우 iso-8859-1) |
| Unicode | 유니코드 문자셋의 UTF-16 인코딩 |
| UTF32 | 유니코드 문자셋의 UTF-32 인코딩 |
| UTF8 | 유니코드 문자셋의 UTF-8 인코딩 |
효율성과 호환성 측면에서 UTF-8 인코딩 방식이 가장 널리 사용되는 추세이다.
UTF-8은 가변 길이 인코딩 방식으로, 영문과 ASCII 문자는 1바이트로 표현할 수 있기 때문에 저장 공간을 효율적으로 사용할 수 있다.
또한 웹, 리눅스, 대부분의 네트워크 프로토콜에서 사실상의 표준 인코딩으로 사용되고 있기 때문에 호환성 측면에서도 장점이 있다.
이러한 이유로 현대의 많은 시스템과 플랫폼에서는 기본 인코딩으로 UTF-8을 사용하는 경우가 많다.
System.Text.RegularExpression.Regex
정규 표현식(Regular Expression)은 문자열의 특정 패턴을 표현하기 위한 형식 언어이다.
문자열에서 특정 규칙을 가진 데이터를 찾거나, 입력값을 검증하거나, 문자열을 치환하는 등의 작업을 효율적으로 처리할 수 있다.
정규 표현식은 매우 다양한 문법을 가지고 있지만, 여기서는 C#에서 기본적으로 사용되는 정규 표현식의 활용 방법을 중심으로 확인했다.
웹 사이트에 회원가입을 하다 보면 전자 메일 주소를 입력한다.
그런 경우 입력된 문자열이 전자 메일 형식에 어긋나면 정상적인 메일 주소를 입력하라는 메시지 창이 뜨는데, 이 기능은 어떻게 구현하는가? 이를 위해 우선 허용되는 전자 메일의 규칙을 정리해야 한다.
- 반드시 @ 문자를 한번 포함해야 한다.
- @ 문자 이전의 문자열에는 문자와 숫자만 허용된다.(특수문자 포함 x)
- @ 문자 이후의 문자열에는 문자와 숫자만 허용되지만 반드시 하나 이상의 점(dot)을 포함해야 한다.
이런 규칙에 따라 코드를 만들면 다음과 같다.
internal class StrStudy
{
static void Main(string[] args)
{
string email = "tester@test.com";
Console.WriteLine(IsEmail(email)); //출력 결과 : true
}
static bool IsEmail(string email)
{
string[] parts = email.Split('@');
if(parts.Length != 2)
{
return false;
}
if (IsAlphaNumeric(parts[0]) == false)
{
return false;
}
parts = parts[1].Split('.');
if (parts.Length == 1)
{
return false;
}
foreach(string part in parts)
{
if(IsAlphaNumeric(part) == false)
{
return false;
}
}
return true;
}
static bool IsAlphaNumeric(string text)
{
foreach(char ch in text)
{
if(char.IsLetterOrDigit(ch) == false)
{
return false;
}
}
return true;
}
}비교를 위해 이와 동일한 기능을 정규 표현식으로 구현
전자 메일 형식을 만족하는 정규 표현식
^(0-9a-zA-Z+)@([0-9a-zA-Z]+)(\.[0-9a-zA-Z]+){1,}$
^: 문장의 시작이 다음 규칙을 만족해야 한다.
([0-9a-zA-Z]+): 영숫자가 1개 이상
@: 반드시 '@' 문자가 있다.
([0-9a-zA-Z]+): 영숫자가 1개 이상
(\.[0-9a-zA-Z]+):점(.)과 1개 이상의 영숫자
{1,}: 이전의 규칙이 1번 이상 반복(즉, 점과 1개 이상의 영숫자가 반복)
$: 이전의 규칙을 만족하면서 끝남(즉, 점과 1개 이상의 영숫자가 1번 이상 반복되면서 종료)
이렇게 추출된 문자열로 코드를 만들면 다음과 같다.
internal class StrStudy
{
static void Main(string[] args)
{
string email = "tester@test.com";
Console.WriteLine(IsEmail2(email)); //출력 결과 : true
}
static bool IsEmail2(string email)
{
Regex regex =
new Regex(@"^([0-9a-zA-Z]+)@([0-9a-zA-Z]+)(\.[0-9a-zA-Z]+){1,}$");
return regex.IsMatch(email);
}
}Regex 타입에는 패턴 일치를 판단하는 IsMatch 메서드뿐 아니라 패턴과 일치하는 문장을 다른 문장으로 치환하는 Replace 메서드도 제공된다.
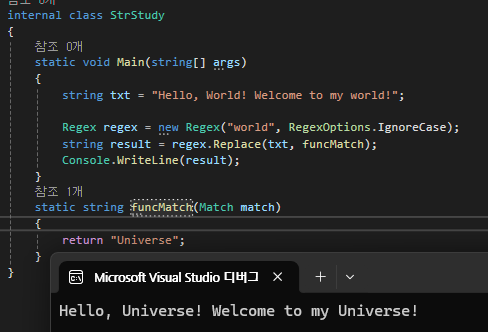
Regex 타입의 Replace 메서드는 생성자에서 지정한 패턴(pattern) 을 기준으로 첫 번째 인자로 전달된 문자열에서 일치하는 부분을 찾는다.
패턴에 해당하는 문자열을 발견하면 Replace 메서드는 두 번째 인자로 전달된 델리게이트 메서드를 호출한다. 이 델리게이트는 Match 객체를 전달받고, 반환하는 문자열을 통해 실제 치환될 값을 결정한다.
즉, Replace 메서드는 단순히 문자열을 바꾸는 것이 아니라 패턴에 일치하는 문자열을 찾은 뒤, 델리게이트 메서드의 반환값으로 해당 부분을 교체하는 방식으로 동작한다.
예를 들어 위의 코드에서는 대소문자 구분 없이 world 단어를 검색하도록 패턴을 설정했다.
패턴에 해당하는 문자열이 발견될 때마다 델리게이트 메서드인 funcMatch가 호출되고, 이 메서드가 "Universe" 문자열을 반환하기 때문에 결과 문자열에서는 world가 "Universe"로 치환된다.
참고로 string 타입에서도 Replace 메서드를 제공하기 때문에 단순한 문자열 치환이라면 굳이 Regex를 사용할 필요는 없다.
하지만 특정 패턴을 기반으로 문자열을 찾거나 조건에 따라 다른 방식으로 치환해야 하는 경우에는 Regex가 훨씬 유용하다.

Reference
시작하세요! C# 12 프로그래밍 기본 문법부터 실전 예제까지
'C#' 카테고리의 다른 글
| C# BCL(Base Class Library) - 컬렉션 (0) | 2026.03.09 |
|---|---|
| C# BCL(Base Class Library) - 직렬화/역직렬화 (0) | 2026.03.07 |
| C# BCL(Base Class Library) - 시간 (0) | 2026.03.05 |
| C# 1.0 - 힙과 스택 (0) | 2025.09.26 |
| C# 1.0 - 예외 (0) | 2025.09.24 |