일반적으로 프로그램을 실행하면 프로그램의 코드는 메모리에 적재된다.
메모리상의 코드는 CPU에 의해 하나씩 읽히면서 실행되는데, 이 과정에서 프로그램은 자연스럽게 데이터를 위한 메모리가 필요해진다. 그에 따라 메모리는 코드와 데이터로 채워진다.
힙과 스택은 데이터를 위한 메모리라는 점에서 같은 성질을 띄지만 메모리의 용도에 따라 구분된다.
스택
Stack은 스레드가 생성되면 기본적으로 1MB의 용량으로 스레드마다 할당되고, 자료구조에서 다루는 스택과 동작 방식이 같다.
이 스택 공간을 활용해서 스레드는 메서드의 실행, 해당 메서드로 전달하는 인자, 메서드 내에서 사용되는 지역 변수를 처리한다.
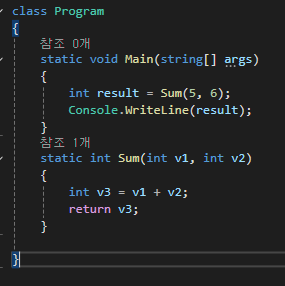
스레드가 Sum 메서드를 호출하는 과정에서 스레드에 할당된 수택에 5와 6의 4바이트 정수값과 Sum 메서드를 호출한 후 실행이 재개될 Main 메서드의 코드 주소를 넣어둔다.
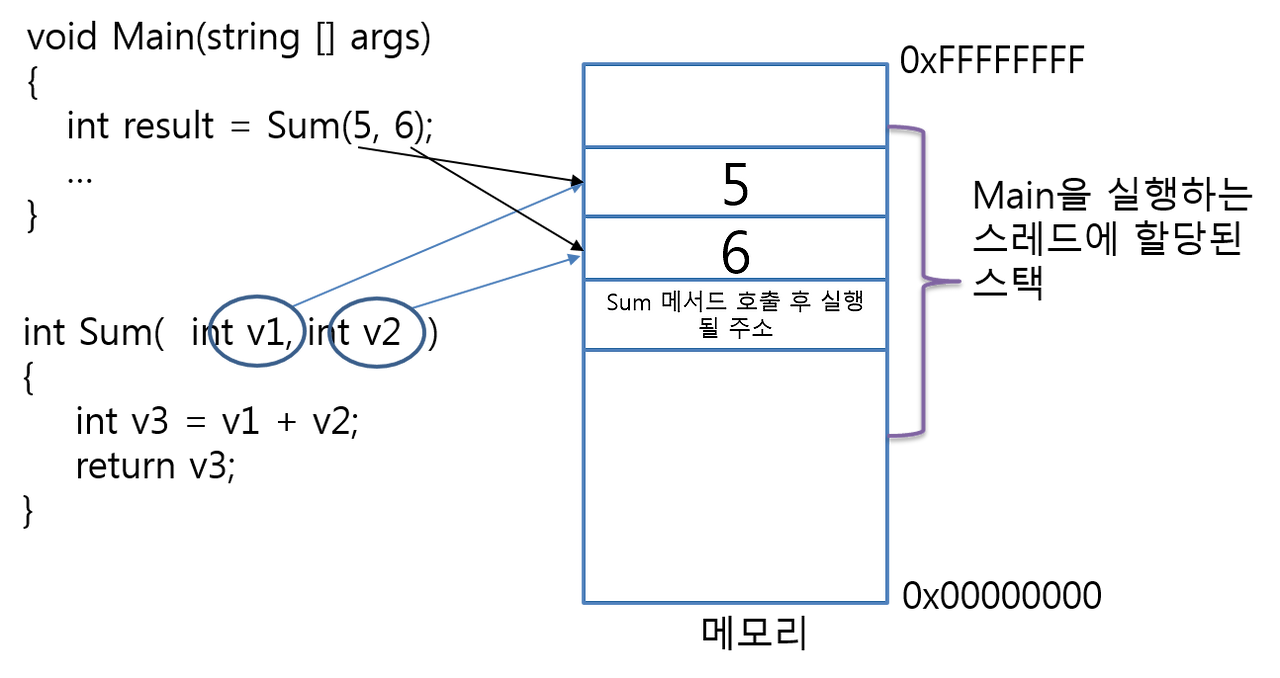
// 그림에서 스택 연산을 순서대로 표현하면 다음과 같다
PUSH 5
PUSH 6
PUSH[Sum 메서드 호출 후 실행될 주소]
// 스택은 메모리의 높은 주소에서 낮은 주소 방향으로 자라난다.
// 따라서 PUSH할 때마다 스택 포인터가 감소하며,
// 먼저 PUSH된 값일수록 메모리 상에서는 더 높은 주소에 저장된다.스레드는 메서드의 코드를 실행하기 전에 지역 변수를 위한 메모리를 추가로 스택에 할당하는 과정을 거친다.
지역 변수에 필요한 메모리의 양은 C# 컴파일러가 Sum 메서드를 컴파일하는 과정에서 알 수 있고, 위의 예제에서는 int v3 하나이므로 4바이트 공간을 확보한다.
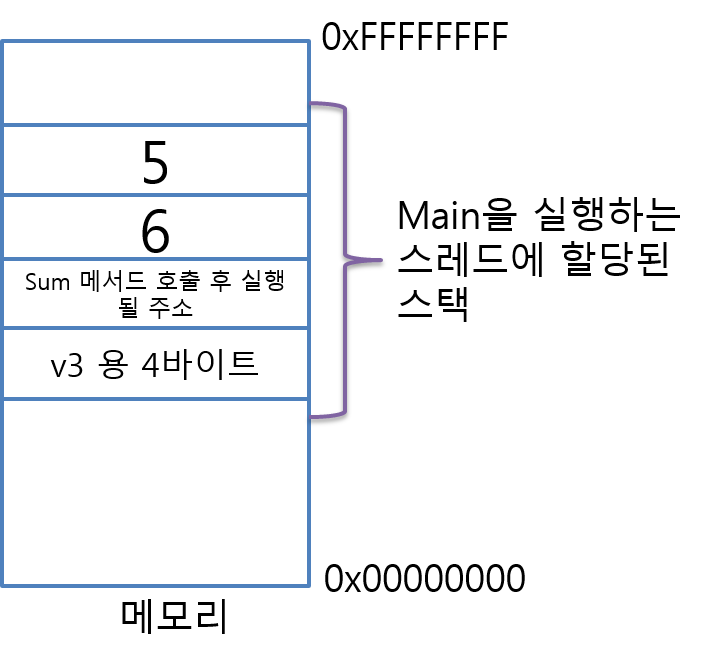
Sum 메서드의 실행이 완료되면 차례대로 스택에서 값들이 제거되는 과정을 거친다.
Sum 메서드를 호출하기 전과 호출 후의 스택에는 변함이 없다. 이처럼 스택은 그것이 속한 스레드가 메서드를 호출할 때마다 증가하고 줄어드는 과정을 반복한다. 스택 자료구조 하나만으로 인자 전달과 지역 변수, 메서드의 실행 흐름을 제어할 수 있게 된 것이다.
메서드 호출과 스택의 관계
메서드 호출은 내부적으로 스택(stack) 을 적극적으로 활용합니다.
C# 같은 고수준 언어에서도 결국 JIT이 네이티브 코드로 바꿔 실행할 때는 이 규칙을 따릅니다.
메서드 호출 시 스택의 역할
스택은 "임시 저장 공간"입니다.
메서드 호출 과정에서 크게 3가지가 스택에 올라갑니다:
- 매개변수 (arguments)
호출할 함수에 전달할 값이 스택에 PUSH 됩니다. (레지스터 최적화 안 할 경우) - 리턴 주소 (return address)
함수가 끝난 뒤 다시 돌아올 코드 위치를 스택에 PUSH 합니다.
(CALL 명령어가 자동으로 수행) - 지역 변수와 임시 값 (local variables)
함수 안에서 선언된 지역 변수들이 스택 프레임에 저장됩니다.
스택 프레임(Stack Frame)
함수가 호출될 때마다 스택 프레임이라는 구조가 생깁니다.
- 프롤로그 (함수 진입 시):
- 현재 스택 포인터를 기준으로 새로운 프레임을 만듦
- 지역 변수를 위한 공간 확보
- 에필로그 (함수 종료 시):
- 프레임 해제
- 리턴 주소를 POP해서 원래 위치로 돌아감
정리
- 메서드 호출 시 스택은 인자 전달, 리턴 주소 저장, 지역 변수 관리를 담당한다.
- 함수가 호출될 때마다 독립된 스택 프레임이 생성되고, 함수 종료 시 해제된다.
- 이 구조 덕분에 재귀 호출이 가능하다. (호출마다 스택 프레임이 따로 생기기 때문)
- C# 컴파일러는 IL 코드만 생성하며, 실제 스택 처리와 같은 저수준 기계어 코드는 JIT 컴파일러에 의해 실행 시점에 만들어진다.
스택 오버플로
스택은 기본적으로 1MB 공간만 스레드에 할당한다 1MB 용량은 경우에 따라 매우 클 수도 있고 작을 수도 있다.
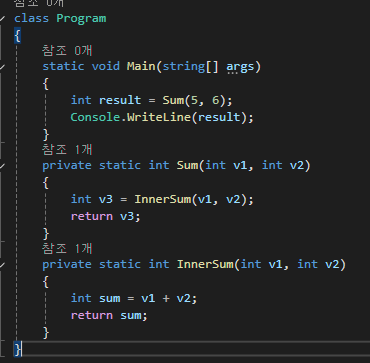
Sum은 또 다시 InnerSum 메서드를 호출한다.
2개의 메서드 모두 2개의 인자를 받고 1개의 지역 변수를 사용하고 있으므로 각 호출마다 16바이트의 스택 메모리를 소비한다. Main → Sum → InnerSum 호출이 중첩되었기에 InnerSum 코드를 실행하는 동안 스택에 32바이트가 점유된다.
이처럼 스택은 메서드 호출이 깊어질수록 함께 사용량이 늘어난다.
스레드별 스택은 기본적으로 수 MB 정도로 제한되어 있으며(전통적으로 약 1MB), 이 한계를 넘으면 **스택 오버플로(Stack Overflow)**가 발생한다.
StackOverflowException이 발생하면 try/catch 여부와 상관없이 프로세스가 종료된다.
이는 예외 처리기 실행에도 스택 공간이 필요한데, 이미 한계에 도달했기 때문에 안전하게 복구할 수 없기 때문이다.
일반적인 메서드 호출에서는 문제가 되지 않지만, 무한 재귀 호출과 같은 경우에는 쉽게 스택을 고갈시켜 문제가 발생할 수 있다.
재귀호출
재귀 호출(recursive call)이란 메서드 내에서 자기 자신을 다시 호출하는 것을 말한다. 재귀 호출을 말할 때 드는 예시가 바로 계승(Factorial)을 구하는 코드이다.

재귀 호출은 특정 문제(트리, 그래프 탐색이나 분할 정복 알고리즘 등)를 표현할 때 코드를 단순하고 직관적으로 만들 수 있다.
하지만 단점도 존재한다.
- 호출이 깊어질수록 콜 스택이 과도하게 쌓여 스택 용량을 초과할 수 있으며, 이 경우 StackOverflowException이 발생한다.
- 함수 호출 자체에도 스택 프레임을 만드는 비용이 있어, 단순 반복문보다 성능이 떨어질 수 있다.
따라서 재귀 호출은 코드 가독성에는 유리하지만, 스택 사용량과 성능을 고려해 반복문으로 바꿀 수 있는 경우는 반복문을 선택하는 것이 안전하다.
재귀호출을 사용하다 스택오버플로 예외가 발생했을 때 소스코드의 라인 정보가 출력되지 않는다.
→ 예외 객체를 생성하고, 스택 트레이스를 기록하고, catch 블록으로 제어를 넘기려면 또다시 스택 공간이 필요한데, 여유 공간이 없어 CLR은 안전성을 위해 트레이스 기록을 포기하고 프로세스를 강제 종료한다.
결과적으로 소스 코드의 라인 정보(Stack Trace)가 출력되지 않고 그냥 프로그램이 죽어버린다.
참고로 릴리즈 빌드에서는 꼬리 호출 최적화가 적용될 수 있어서, 일부 재귀는 스택 오버플로 없이 실행될 수 있다.
힙
- .NET에서 "힙"이라고 하면 기본적으로 **관리 힙(Managed Heap)**을 의미한다.
- 관리 힙은 CLR의 **가비지 수집기(GC)**가 메모리 할당과 해제를 자동으로 관리하기 때문에 붙여진 이름이다.
- new 키워드로 생성되는 **참조형 객체(클래스, 배열, 델리게이트 등)**는 모두 관리 힙에 올라간다.
- C#에는 C/C++처럼 직접 메모리를 해제하는 명령어가 없으며, 해제는 GC가 참조가 끊긴 객체를 자동으로 수거한다.
네이티브 응용 프로그램에서는 개발자가 주의 깊게 할당과 해제 쌍을 맞춰야 한다. 할당만 하고 해제를 잊어버리면 해제되지 않은 메모리가 누적되어 메모리 부족 현상이 발생할 수 있다. → 메모리 누수 현상(memory leak)이라 한다.
관리 응용 프로그램에서는 GC 덕분에 메모리 누수 현상을 겪을 위험은 많이 줄어들었다.
C# 프로그램은 코드가 실행되면서 new로 필요한 객체를 힙에 할당한다.
메모리는 무한으로 사용 가능한 자원이 아니다. 따라서 일정 수준의 메모리 할당이 발생하면 GC가 동작한다.
GC는 힙에 있는 객체 중에서 현재 사용되지 않는 객체는 제거함으로써 여유 공간을 확보한다.
GC 동작은 프로그램의 다른 동작을 중지시킨다는 것을 염두해야 한다.
힙을 많이 사용할 수록 GC는 더 자주 동작하고, 그만큼 프로그램은 빈번하게 실행이 중지되어 성능 문제를 겪을 수 있다.
박싱/언박싱
- 박싱(Boxing): 값 형식(value type)을 참조 형식(reference type, object)으로 변환하는 과정.
- 언박싱(Unboxing): 박싱된 객체를 다시 원래 값 형식으로 변환하는 과정.
- 박싱/언박싱은 object 타입과 System.ValueType을 상속받은 값 형식의 인스턴스를 섞어 사용할 때 발생한다.
- 이 과정은 힙에 객체를 생성하고 값이 복사되므로, 성능 비용이 존재한다.

박싱과 언박싱이 중요한 이유
- 값 형식을 object로 변환하는 박싱 과정은 힙에 메모리 할당과 값 복사를 동반한다.
- 이러한 변환은 메서드 호출 시 인자를 object 타입으로 전달할 때도 발생한다.
- 따라서 박싱/언박싱은 불필요한 메모리 사용과 성능 저하의 원인이 될 수 있으며, 필요시 제네릭(Generic) 사용으로 피할 수 있다.

- 값 형식을 object 참조형에 할당하면 힙에 메모리가 할당되고 값이 복사된다 → 박싱 발생.
- 박싱된 객체는 GC가 나중에 회수하며, 박싱이 많을수록 GC가 자주 동작 → 프로그램 성능 저하.
- 따라서 박싱이 불필요하게 발생할 수 있는 코드는 최소화하는 것이 좋다.
.NET BCL에서도 값 형식 박싱으로 인한 성능 손실을 줄이기 위한 설계가 존재한다.
- Console.WriteLine은 대표적인 사례:
- Console.WriteLine(object value)는 박싱 가능
- 그러나 Console.WriteLine(int value), Console.WriteLine(double value) 등 값 형식 전용 오버로드를 제공하여 박싱 없이 처리 가능
public static void WriteLine(bool value);
public static void WriteLine(char value);
public static void WriteLine(decimal value);
public static void WriteLine(double value);
public static void WriteLine(float value);
public static void WriteLine(int value);
public static void WriteLine(long value);
public static void WriteLine(uint value);
public static void WriteLine(ulong value);
public static void WriteLine(char[] value);
public static void WriteLine(string value);
public static void WriteLine(object value);가비지 수집기(Garbage Collector, GC)
CLR의 힙은 세대(generation)로 나뉘어 관리된다. 처음 new로 할당된 객체는 0세대(generation 0)에 속한다.
이는 GC 타입을 이용해 코드로도 알아낼 수 있다.

- 새로 생성된 객체는 모두 **0세대(Gen0)**에 속한다.
- 0세대 총 용량이 일정 수준을 넘어가면 0세대 GC가 실행된다.
- 사용되지 않는 객체는 제거
- 살아남은 객체는 **1세대(Gen1)**로 승격
- 프로그램이 진행되면서 1세대 총 용량이 일정 수준을 넘어가면 0~1세대 GC가 실행된다.
- 살아남은 객체는 **2세대(Gen2)**로 승격
- 2세대 총 용량이 일정 수준을 넘어가면 0~2세대 GC가 실행된다.
- 2세대가 최대 세대이며, 살아남은 객체는 계속 2세대에 존재
- 2세대 메모리 공간은 시스템이 허용하는 범위까지 계속 확장될 수 있다.
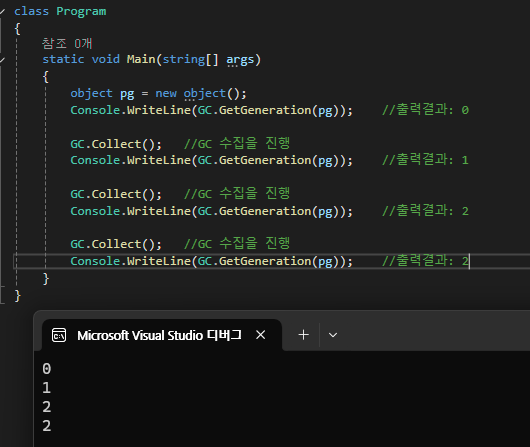
GC.Collect의 호출로 가비지 수집이 된 이후부터는 승격해서 그 다음 세대로 넘어가며 2세대 이후부터는 같은 세대를 유지한다.

GC 동작 요약
- 0세대(G0)
- 새 객체 할당 시 먼저 여기에 위치
- 총 용량 초과 시 GC 실행 → 살아남은 객체는 1세대로 승격
- 1세대(G1)
- 0세대에서 살아남은 객체가 승격
- 총 용량 초과 시 0~1세대 GC 실행 → 살아남은 객체는 2세대로 승격
- 2세대(G2)
- 1세대에서 살아남은 장수 객체가 승격
- 총 용량 초과 시 0~2세대 GC 실행
- 2세대가 최대 세대 → 계속 2세대에 남아 있음
포인트
- 세대별 GC는 젊은 객체일수록 자주 수거하고, 장수 객체는 적게 수거하도록 최적화되어 있음
- 이를 통해 GC 성능을 높이고 프로그램 중단 시간을 최소화함
- 관리 힙은 프로그램 실행 시 하나의 힙 공간으로 만들어진다.
- 세대 구분(0~2세대)은 힙 내부 포인터를 통해 관리되는 논리적 구분일 뿐, 프로그램에서는 하나의 힙.
- 힙 객체를 참조하는 스택 변수, 레지스터, 다른 객체를 루트 참조(root reference)라고 한다.
- 가비지 수집 시 루트 참조가 있는 객체는 살아남고, 루트 참조가 없는 객체는 제거된다.
전체 가비지 수집
세대별 GC 동작 원리
- 세대 구분의 이유
프로그램 실행 중 대부분의 객체는 0세대에서 빠르게 생성되고 빠르게 소멸한다는 통계적 근거에 기반.
→ 따라서 젊은 객체(0세대)를 집중적으로 수거하는 것이 효율적. - 0세대 GC (Minor GC)
0세대에 객체가 꾸준히 생성·해제되며, 기준 용량을 초과하면 GC는 0세대 힙에 대해서만 빠르게 수거를 수행. - 1세대로의 승격
0세대만 수거하다 보면 장수 객체가 1세대로 이동(승격)하면서 1세대 힙 크기가 점점 커짐. - 1세대 GC
0세대 수거만으로 부족할 경우, 0세대 + 1세대까지 GC가 실행됨. - 2세대 및 Full GC
이마저도 부족할 경우 **모든 세대(0~2세대)를 대상으로 한 전체 가비지 수집(Full GC)**이 발생.
→ 프로그램 중단 시간이 가장 길어짐. - 명시적 GC
GC.Collect(int generation) 메서드를 통해 개발자가 직접 특정 세대의 GC를 강제로 실행할 수도 있음. (일반적으로는 권장되지 않음)
| 메서드 | 인자 | 수집대상 |
| GC.Collect(int generation) | 0 | 0세대 힙만을 가비지 수집 |
| 1 | 0과 1세대 힙만을 가비지 수집 | |
| 2 | 0, 1, 2세대 전체에 걸쳐 가비지 수집 |
GC.Collect의 세대별 가비지 수집 기능
GC.Collect 사용 목적
- 주된 목적
보통은 CLR의 GC가 자동으로 최적의 시점에 실행되지만,
특정 상황에서 개발자가 직접 명시적으로 가비지 수집을 요청할 수 있음. - 사용 이유
- 매우 큰 객체(예: 수백 MB 단위의 배열, 대용량 이미지 등)를 생성 후 더 이상 사용하지 않을 때,
→ 즉시 메모리를 해제하고 싶을 때 - 짧은 시간 안에 메모리 사용량을 줄여야 하는 경우 (예: 대규모 데이터 처리 후 한 텀 쉬는 구간)
- 리소스가 제한된 환경(임베디드, 모바일)에서 메모리 확보를 위해
- 매우 큰 객체(예: 수백 MB 단위의 배열, 대용량 이미지 등)를 생성 후 더 이상 사용하지 않을 때,
- 주의할 점
- 자주 사용하면 오히려 성능 저하 발생 (GC는 매우 무거운 연산이라 프로그램 중단 시간이 길어짐).
- 일반적으로는 CLR에게 맡기는 것이 최적이며,
GC.Collect()는 예외적인 상황에서만 권장됨.
LOH (Large Object Heap, 대용량 객체 힙)
- 할당 기준
- 일반 관리 힙과 달리 85,000 바이트(약 83KB) 이상 크기의 객체는 LOH에 할당됨.
- 흔히 대규모 배열, 대형 문자열, 버퍼 같은 것들이 LOH에 들어감.
- GC 동작 차이
- 일반 힙의 객체는 세대별 GC(Gen 0 → Gen 1 → Gen 2)를 거치며 살아남으면 승격되고, 이동(compaction)도 이루어짐.
- 하지만 LOH는 compaction(압축 이동)을 하지 않음 → 객체의 메모리 주소가 바뀌지 않음.
- 이유: 매번 수 MB~수십 MB짜리를 이동시키면 GC 성능이 너무 떨어지기 때문.
- 문제점
- LOH는 compaction을 하지 않기 때문에 해제된 영역이 그대로 구멍으로 남음 → 메모리 파편화(fragmentation) 발생.
- 그 결과 충분한 총 여유 메모리가 있어도, 연속된 큰 메모리 블록이 없으면 새 큰 객체를 할당할 수 없어 OutOfMemory 예외가 날 수 있음.
- Full GC와 LOH
- LOH도 Full GC 시점에만 수집 대상이 됨.
- 따라서 자주 GC 대상이 되지 않아 큰 객체가 계속 쌓이면 메모리 압박이 심해질 수 있음.
ex) 총 100MB 용량의 LOH가 만들어졌다고 가정하며, 각각 20MB, 40MB에 해당하는 객체가 생성되면 힙은 다음과 같은 상태가 된다.

이후 20MB 객체가 필요없어지고 GC가 발생하면 다음과 같이 객체의 위치가 변하지 않은 채로 파편화가 진행된다.

총 60MB의 여유 공간이 있음에도 응용 프로그램이 50MB 객체를 생성하려고 시도하면 연속적으로 할당할 수 있는 공간이 없으므로 메모리가 부족하다는 오류가 발생 → 따라서 용량을 크게 차지하는 객체는 주의 깊게 사용해야 한다.
LOH의 또 다른 특징으로는 그 힙에 생성된 객체는 초기부터 2세대에 해당한다는 점이다. 이 때문에 FullGC가 발생하지 않는 한 LOH의 객체는 수집 과정을 거치지 않는다.
정리
LOH의 세대(Generation) 특징
- 일반 힙 객체
- 처음 생성 시 0세대에 들어감.
- GC가 돌면서 살아남으면 1세대, 2세대로 승격.
- LOH 객체
- 처음 생성될 때부터 2세대(Gen 2)에 속함.
- 따라서 Gen 0, Gen 1 수집에서는 전혀 영향을 받지 않음.
- 즉, Full GC가 발생해야만 LOH 객체가 수집 대상이 됨.
- 장점
- 큰 객체를 매번 0세대에서 승격시키는 과정을 거치지 않음 → 불필요한 승격 비용 절약.
- 메모리 주소가 바뀌지 않기 때문에 고정된 버퍼 같은 시나리오에 안정적.
- 단점
- Full GC 때만 정리되므로, 한번 LOH에 올라간 큰 객체는 꽤 오래 남아있을 가능성이 높음.
- 게다가 compaction(압축 이동)을 하지 않으므로 파편화 문제까지 발생할 수 있음.
자원 해제
GC의 동작으로 객체가 소멸되는 시점을 개발자가 알 수 없다. GC가 언제 동작할지는 CLR 내부에 의해 결정된다.
경우에 따라서는 관리 힙에 객체들이 자주 생성되지 않는다면 오랜 시간 동안 객체가 소멸되지 않을 수도 있다.
자원 해제와 관련한 예시) 파일을 처리하는 것과 관련이 있다.
.NET에서 파일은 FileStream 객체를 통해 조작할 수 있다.
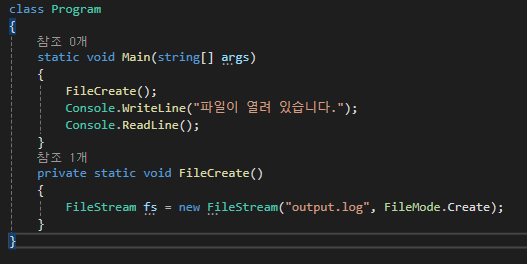
이 프로그램이 실행된 상태에서 윈도우 탐색기를 이용해 output.log 파일을 삭제하면 FileCreate 메서드를 벗어났는데도 output.log 파일이 삭제되지 않는다.
FileStream 객체가 여전히 관리 힙에 남아 있는 상태이고 그 파일을 독점적으로 소유하고 있어 잠겨있기 때문이다.
이처럼 닷넷에서도 GC만 믿고 자원 해제를 소홀히 하는 것은 프로그램 운영에 장애를 가져올 수 있다.
이 때문에 명시적인 자원 해제가 필요한 클래스를 만드는 개발자의 경우 Close 같은 이름의 멤버 메서드를 함께 제공한다.
FileStream도 예외는 아니기 때문에 파일을 열면 닫아야 한다.
private static void FileCreate()
{
FileStream fs = new FileStream("output.log", FileMode.Create);
fs.Close();
}Close를 사용했지만 이 이름이 자원 해제를 대표하는가?
- 이 시점에서 인터페이스를 통한 계약을 활용할 수 있다.
- 마이크로소프트는 자원 해제가 필요하다고 판단되는 모든 객체는 개발자로 하여금 IDisposable 인터페이스를 상속받도록 권장한다.
- 이 인터페이스에 정의된 메서드는 단 하나다.
public interface IDisposable
{
void Dispose();
}FileStream 객체도 IDosposable을 상속받고 있으며, 따라서 Dispose 메서드를 구현하고 있다.
이 때문에 Close 대신 Dispose 메서드를 호출해도 동일하게 파일이 닫힌다.
private static void FileCreate()
{
FileStream fs = new FileStream("output.log", FileMode.Create);
fs.Dispose();
}이것은 인터페이스를 통한 약속이다.
자원 해제를 명시해야 할 것이 있다면 IDisposable 인터페이스를 구현하는 것이 좋다.
어떤 객체가 IDisposable을 구현했다는 건 = "이 객체는 관리되지 않는 자원을 사용하므로 명시적으로 해제해야 한다" 라는 계약을 의미한다.
정리
- Close()는 클래스마다 자원 정리용으로 구현되었지만, 표준화된 계약은 아님.
- 자원 해제를 보장하는 통일된 방법은 IDisposable.Dispose().
- 따라서 .NET에서 자원 해제가 필요한 클래스는 반드시 IDisposable을 구현하도록 권장된다.
class Program
{
static void Main(string[] args)
{
FileLogger log = new FileLogger("Sample.log");
log.Write("Start");
log.Write("End");
log.Dispose();
}
}
class FileLogger : IDisposable
{
FileStream _fs;
public FileLogger(string fileName)
{
_fs = new FileStream(fileName, FileMode.Create);
}
public void Write(string txt)
{
//생략
}
public void Dispose()
{
_fs.Close();
}
}이 FileLogger 클래스를 사용하는 개발자는 IDisposable 인터페이스가 구현되어 있다는 사실을 미루어 해당 객체의 사용이 끝나면 Dispose 메서드를 호출해야 한다는 것을 직관적으로 알 수 있다.
위 코드에 한 가지 문제가 발생할 수 있다. FileLogger 인스턴스를 Dispose하기 전에 예외가 발생한다면?
→ 그로 인해 Dispose 메서드가 호출되지 않아 정상적으로 자원 회수가 불가능할 수 있다.
문제가 발성할 수 있다고 적었지만, 위 코드는 프로그램이 종료되면서 프로세스가 가진 모든 자원이 강제로 회수되기 때문에 파일 잠금도 프로세스가 종료되면서 해제된다.
따라서 IDisposable을 구현하는 객체라면 보통 try/finally를 이용해 Dispose를 호출하는 것이 관례라고 한다.
FileLogger log = null;
try
{
log = new FileLogger("Sample.log");
log.Write("Start");
log.Write("End");
}
finally
{
log.Dispose();
}위의 코드가 다소 번거롭기 때문에 C#은 부가적으로 try/finally를 대신하는 using 예약어를 제공한다.
- 여기서 using은 네임스페이스를 선언하는 using과 이름만 같을 뿐 전혀 다른 역할을 한다.
using (FileLogger log = new FileLogger("Sample.log"))
{
log.Write("Start");
log.Write("End");
}- Dispose 메서드의 호출이 생략되었다.
- using은 괄호 안에서 생성된 객체의 Dispose 메서드를 블록이 끝나는 시점에 자동으로 호출하는 역할을 한다.
- 실제로 using을 이용한 코드는 C# 컴파일러에 의해 내부적으로 완벽하게 동일하게 번역된다.
- 즉, using 예약어는 try/finally/Dispose에 대한 간편 표기법에 해당한다.
요약
using 예약어는 try/finally/Dispose 패턴을 자동으로 생성해 주는 간편 표기법이다. 따라서 IDisposable을 구현한 객체의 자원 해제를 안전하고 간단하게 처리할 수 있다.
종료자
- 종료자(finalizer)란 객체가 관리 힙에서 제거될 때 호출되는 메서드다.
- 종료자를 만들려면 클래스와 동일한 이름으로 ~(틸드:tield)기호만 붙이면 된다.
class UnmanagedMemoryManager
{
~UnmanagedMemoryManager() //종료자
{
Console.WriteLine("수행됨); //관리 힙에서 제거될 때 수행
}
}종료자를 언제 정의해야 하는가?
종료자(finalizer) 정의가 필요한 경우
- 비관리 자원(unmanaged resource) 을 직접 다루는 경우
- 예: HANDLE, FILE*, 소켓 핸들, 데이터베이스 연결 핸들, 네이티브 라이브러리에서 할당한 메모리 포인터 등
- GC는 이 자원들을 추적하지 않으므로, 객체가 해제될 때 개발자가 명시적으로 정리해야 한다.
- 관리 객체가 비관리 자원을 소유하고 있는 경우
- 관리 객체 안에서 비관리 자원을 캡슐화할 때, 안전하게 정리할 방법을 제공해야 한다.
⚠️ 종료자를 피해야 하는 경우
- 단순히 관리 메모리(예: string, List<int> 등) 만 사용하는 경우
→ GC가 알아서 회수하므로 종료자를 정의할 필요가 없다. - 불필요하게 종료자를 정의하면 GC 비용이 커지고 성능에 악영향을 준다.
올바른 패턴 (Dispose + Finalizer)
마이크로소프트 권장 방식은 Dispose 패턴을 따르는 것이다.
class MyResource : IDisposable
{
// 비관리 자원을 나타내는 예 (윈도우 핸들)
private IntPtr handle;
private bool disposed = false;
public MyResource(IntPtr handle)
{
this.handle = handle;
}
// 종료자 (GC가 수거할 때 호출)
~MyResource()
{
Dispose(false);
}
public void Dispose()
{
Dispose(true);
GC.SuppressFinalize(this); // 종료자 호출 생략
}
protected virtual void Dispose(bool disposing)
{
if (!disposed)
{
// 비관리 자원 해제
if (handle != IntPtr.Zero)
{
CloseHandle(handle);
handle = IntPtr.Zero;
}
// 관리 자원 해제 (disposing == true일 때만)
if (disposing)
{
// 예: managedStream.Dispose();
}
disposed = true;
}
}
[DllImport("Kernel32")]
private static extern bool CloseHandle(IntPtr handle);
}정리
- 종료자는 비관리 자원을 다룰 때만 정의한다.
- 하지만 종료자 하나만 두는 게 아니라, 보통 IDisposable + 종료자를 함께 구현한 Dispose 패턴을 권장한다.
- 이렇게 하면:
- using 문에서 Dispose()로 즉시 해제 가능하다.
- 혹시 개발자가 Dispose()를 안 불러도, GC가 종료자를 통해 마지막 안전장치를 제공한다.
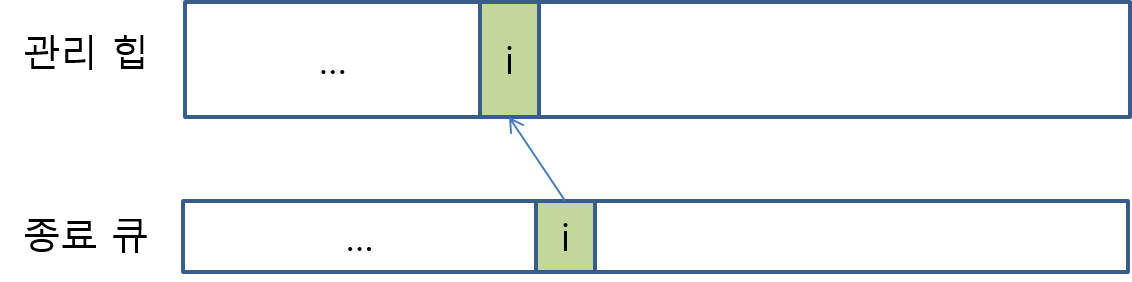
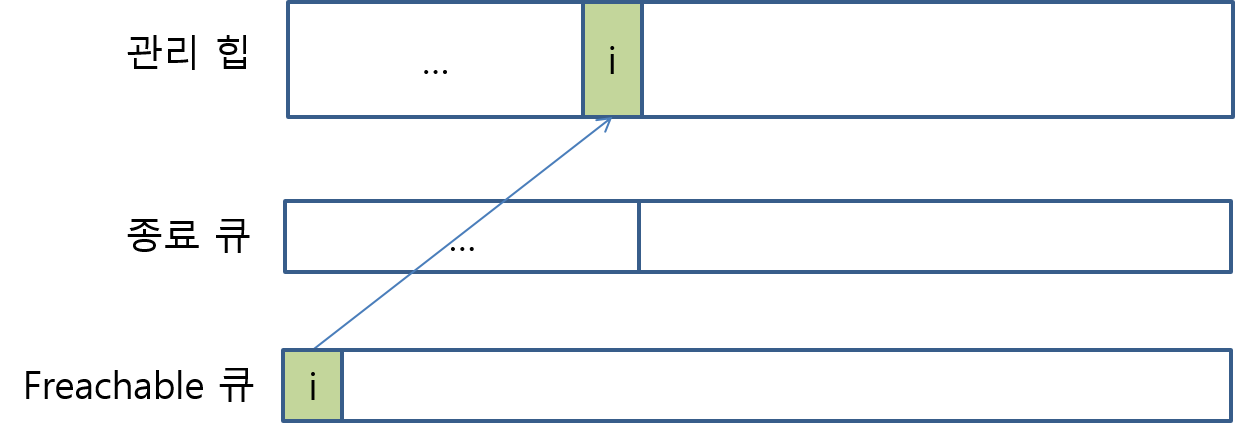
- Freachable큐에 들어온 객체를 CLR에 의해 미리 생성해 둔 스레드가 꺼내고 그것의 종료자 메서드를 호출해준다.
- 이 스레드는 Freachable 큐에 항목이 들어올 때마다 해당 객체를 꺼내서 종료자를 실행하는 역할만 담당하는 특수한 목적의 스레드이다.
- 따라서 대개 위의 상황이 되면 Freachable 큐는 다시 비어있는 상태로 바뀐다.
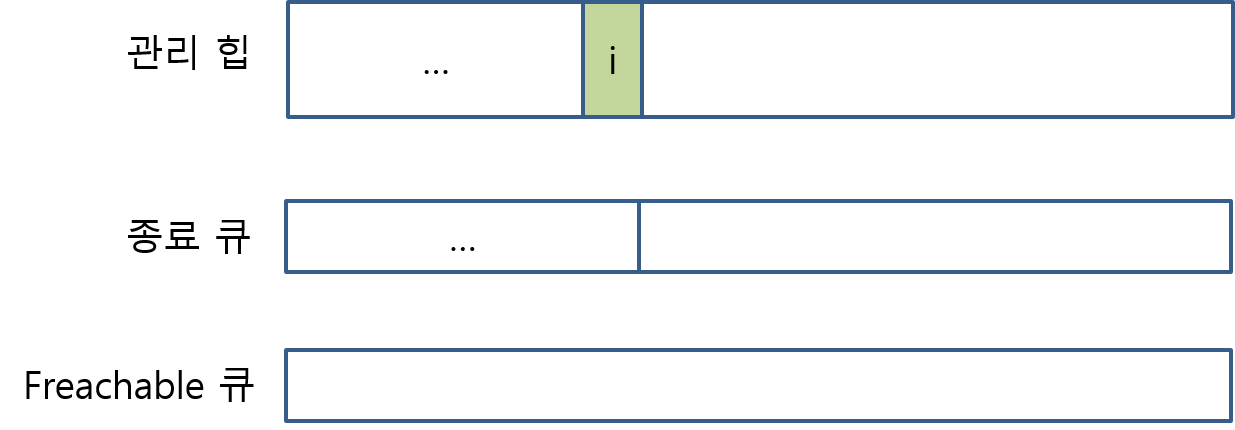
- 위의 상태가 되면 종료자를 가졌던 객체는 종료자를 가지지 않았던 일반 객체와 같은 상태로 변경된다.
- 이후 B 지점에서 다시 한번 GC가 동작하면 객체 i 는 관리 힙에서 제거된다.
간단하게 정리
- 종료자가 구현된 클래스는 GC에 더 많은 일을 시킨다.
- 이 때문에 특별한 이유가 없다면 종료자를 추가하지 않는 것을 권장한다.
- 종료자는 개발자가 Dispose 메서드를 명시적으로 호출했다면 굳이 호출할 필요가 없다.
- Dispose가 호출된 객체는 GC가 그 객체를 관리 힙에서 제거하는 과정에서 종료 큐에 대한 고려를 하지 않아도 된다.
- 마이크로소프트에서는 이처럼 명시적인 자원 해제가 됐다면 종료 큐에서 객체를 제거하는 GC.SuppressFinalize 메서드를 제공한다. 이 메서드를 이용해 Dispose와 종료자를 다음과 같이 재정의 가능하다.
class UnmanagedMemoryManager : IDisposable
{
//생략
void Dispose(bool disposing)
{
if(_disposed == false)
{
Marshal.FreeCoTaskMem(ptrBuffer);
_disposed = true;
}
if(disposing == false)
{
//disposing이 false인 경우란 명시적으로 Dispose()를 호출한 경우다.
//따라서 종료 큐에서 자신을 제거해 GC의 부담을 줄인다.
GC.SuppressFinalize(this);
}
}
public void Dispose()
{
Dispose(false);
}
~UnmanagedMemoryManager()
{
Dispose(true);
}
}위에 구현된 객체를 new로 생성하면 종료 큐에 객체가 추가된다.
- 개발자가 Dispose 메서드를 호출한 경우 GC.SuppressFinalize가 실행됨으로써 종료 큐에서 제거된다.
- 따라서 종료자가 정의되지 않은 객체와 동일한 상태로 바뀌기 때문에 결과적으로 GC의 부담을 덜어준다.
- 코드 자체가 재사용할 수 있는 패턴이기 때문에, 비관리 자원을 해제해야 할 상황이 생기면 Marshal.FreeCoTaskMem 메서드를 호출하는 부분만 직접 코드로 교체해서 사용하면 된다.
요약
- Dispose 호출 → 자원 해제 + GC.SuppressFinalize(this)
- 종료자 큐에서 제거 → GC 오버헤드 감소
- 패턴 재사용 가능 → 다른 비관리 자원 처리에도 그대로 적용 가능
Reference
시작하세요! C# 12 프로그래밍 기본 문법부터 실전 예제까지
'C#' 카테고리의 다른 글
| C# 1.0 - 예외 (0) | 2025.09.24 |
|---|---|
| C# 1.0 - 프로젝트 구성 (0) | 2025.09.24 |
| C# 1.0 - 연산자 (0) | 2025.09.23 |
| C# 1.0 - 문법요소 (0) | 2025.09.21 |
| C# 객체지향 문법 [C#의 클래스 확장 - 멤버 유형 확장] (4) | 2025.07.26 |