프로그래밍하다 보면 정해지지 않은 크기의 배열을 다루기도 한다. 이런 기능을 편리하게 구현한 것을 컬렉션(collectiuon)이라 한다.
BCL에서는 System.Collections 네임스페이스 하위에 이와 관련된 타입을 묶어서 제공한다.
System.Collections.ArrayList
ArrayList는 Object 타입을 기반으로 데이터를 저장하는 컬렉션이다.
Object 타입으로 형 변환이 가능한 모든 타입을 요소로 추가할 수 있으며, 컬렉션에 데이터를 추가 / 삭제 / 변경 / 조회하는 기능을 제공한다.
또한 ArrayList는 배열과 달리 크기가 고정되어 있지 않고 동적으로 변경되는 특징을 가진다.
즉, ArrayList는 크기가 자유롭게 변할 수 있는 동적 배열(Dynamic Array)이라고 볼 수 있다.

ArrayList는 내부적으로 Object 타입을 기반으로 데이터를 저장하는 컬렉션이다. 따라서 Object로 형 변환이 가능한 .NET의 모든 타입을 요소로 저장할 수 있다.
하지만 Object 타입으로 저장되기 때문에 값 형식(Value Type)을 추가할 경우 Boxing / Unboxing이 발생한다는 단점이 있다.
이로 인해 System.ValueType을 상속받는 값 형식 데이터를 많이 사용하는 경우에는 비효율적일 수 있다.
이러한 문제를 해결하기 위해 .NET 2.0부터 Generic 컬렉션이 도입되었으며, ArrayList 대신 List<T> 타입을 사용하는 것이 권장된다.
ArrayList 요소를 정렬할 수 있는 메소드
ArrayList에 저장된 요소는 Sort 메서드를 사용하여 정렬할 수 있다.
배열의 경우에는 Array.Sort(array); 와 같이 정적 메서드(static method)를 사용하지만, ArrayList는 인스턴스 메서드로 Sort()를 제공한다. ArrayList.Sort();
Sort() 메서드를 사용할 때는 다음 조건을 만족해야 한다.
- ArrayList에 저장된 요소는 모두 같은 타입이어야 한다
- 서로 다른 타입이 섞여 있을 경우 ArgumentException 예외가 발생한다

사용자 정의 타입 정렬 방법 (ArrayList.Sort)
ArrayList에 사용자 정의 타입 객체가 저장되어 있을 경우 기본적인 Sort()만으로는 정렬이 불가능하다.
이 경우 다음 두 가지 방법을 사용할 수 있다.
방법 1 : IComparer 인터페이스 사용
IComparer 인터페이스를 구현한 클래스를 만든 후 해당 객체를 Sort() 메서드의 두 번째 인자로 전달하여 정렬 기준을 지정할 수 있다.
즉, 외부에서 비교 기준을 정의하는 방식이다. 이 방법은 정렬 기준을 여러 개 만들어야 할 때 유용하다.
ArrayList.Sort(IComparer comparer)
방법 2 : IComparable 인터페이스 사용
ArrayList.Sort()는 기본적으로 요소의 객체가 IComparable 인터페이스를 구현했는지 확인한다.
만약 구현되어 있다면 내부적으로 메서드를 호출하여 정렬을 수행한다.
즉, 객체 자체가 정렬 기준을 가지고 있는 방식이다. 따라서 IComparable 인터페이스를 구현한 타입이라면 단순히 Sort()만 호출해도 자동으로 정렬된다.
arrayList.Sort();
internal class StrStudy
{
static void Main(string[] args)
{
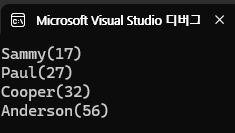
ArrayList arrayList = new ArrayList();
arrayList.Add(new Person(32, "Cooper"));
arrayList.Add(new Person(56, "Anderson"));
arrayList.Add(new Person(17, "Sammy"));
arrayList.Add(new Person(27, "Paul"));
arrayList.Sort();
foreach(Person person in arrayList)
{
Console.WriteLine(person);
}
}
}
public class Person : IComparable
{
public int Age;
public string Name;
public Person(int age, string name)
{
this.Age = age;
this.Name = name;
}
public int CompareTo(object obj) //나이 순서로 정렬
{
Person target = (Person)obj;
if (this.Age > target.Age) return 1;
else if (this.Age == target.Age) return 0;
return -1;
}
public override string ToString()
{
return string.Format("{0}({1})", this.Name, this.Age);
}
}
System.Collections.Hashtable
ArrayList와 함께 사용되는 컬렉션으로 Hashtable이 있다. 이 컬렉션 값(value)뿐만 아니라 해시에 사용되는 키(key)가 추가되어 빠른 검색 속도를 자랑한다. 따라서 검색 속도의 중요도에 따라 ArrayList 또는 Hashtable 중 어느 것을 선택할지 결정한다.
Hashtable이 ArrayList보다 검색이 빠른 이유
ArrayList는 순차 구조이고
Hashtable은 해시 구조이기 때문이다.
ArrayList 검색 방식
ArrayList는 데이터를 순서대로 저장하는 구조이다.
ex) [10, 20, 30, 40, 50]
여기서 40을 찾는다고 하면
이렇게 앞에서부터 하나씩 비교하면서 찾아야 한다.
이를 선형 탐색 (Linear Search) 이라고 한다.
시간 복잡도
데이터가 많아질수록 검색 속도가 점점 느려진다.
Hashtable 검색 방식
Hashtable은 데이터를 Key 기반으로 저장한다.
ex)
"name" → "철수"
"age" → 25
"job" → "developer"
데이터를 저장할 때 Key를 해시 함수에 넣어 인덱스를 계산한다.
예를 들면
↓
해시 함수 계산
↓
바로 3번 위치 접근
시간 복잡도
그래서 검색 속도가 매우 빠르다.
컬렉션에 담긴 항목 수가 많아질 수록 Hashtable의 검색 속도가 ArrayList보다 더욱 빨라진다.
작은 크기의 컬렉션인 경우 ArrayList를 사용해도 무방하다.
static void Main(string[] args)
{
Hashtable hashTable = new Hashtable();
//4개의 요소를 컬렉션에 추가
hashTable.Add("key1", "add");
hashTable.Add("key2", "remove");
hashTable.Add("key3", "update");
hashTable.Add("key4", "search");
//key4 키 값에 해당하는 값을 출력
Console.WriteLine(hashTable["key4"]);
//key3 키 값에 해당하는 요소를 컬렉션에서 삭제
hashTable.Remove("key3");
//key2 키 값에 해당하는 값을 "delete로 변경
hashTable["key2"] = "delete";
Console.WriteLine();
//컬렉션의 모든 키 값을 열람하고, 그 키에 대응되는 값을 출력
foreach(object key in hashTable.Keys)
{
Console.WriteLine("{0} ==> {1}", key, hashTable[key]);
}
}
Hashtable 사용 시 주의점
Hashtable을 사용할 때는 다음과 같은 점을 주의해야 한다.
키(Key) 중복 불가
Hashtable은 Key를 기준으로 데이터를 저장하는 구조이기 때문에 같은 Key를 두 번 추가할 수 없다.
만약 중복된 Key로 Add() 메서드를 호출할 경우 ArgumentException 예외가 발생한다.
따라서 데이터를 추가할 때 Key의 중복 여부를 반드시 확인해야 한다.
메모리 사용 증가
ArrayList는 값(Value)만 저장하지만 Hashtable은 Key와 Value를 모두 저장해야 한다.
따라서 ArrayList < Hashtable 순으로 메모리 사용량이 더 많아질 수 있다.
Boxing / Unboxing 문제
Hashtable은 내부적으로 Key와 Value를 모두 Object 타입으로 저장한다.
따라서 값 형식(Value Type)을 저장할 경우Boxing / Unboxing이 발생할 수 있다.
이로 인해 성능 저하가 발생할 수 있다.
System.Collections.SortedList
SortedList는 ArrayList와 이름은 비슷하지만 실제 사용 방식은 Hashtable과 유사한 Key / Value 구조의 컬렉션이다.
Hashtable에서는 Key가 해시 함수에 의해 변환되어 내부 인덱스를 찾는 용도로 사용된다.
반면 SortedList에서는 Key 자체가 정렬 기준이 되며, Key 값을 기준으로 자동으로 정렬된 상태로 데이터를 저장한다.
즉, SortedList는 데이터를 추가하면 Key를 기준으로 정렬된 상태를 유지한다.
SortedList sortedList = new SortedList();
sortedList.Add(32, "Cooper");
sortedList.Add(56, "Anderson");
sortedList.Add(17, "Sammy");
sortedList.Add(27, "Paul");
foreach(int key in sortedList.GetKeyList())
{
Console.WriteLine(string.Format("{0} {1}", key, sortedList[key]));
}
SortedList 특징
SortedList는 요소를 추가할 때마다 자동으로 정렬되는 컬렉션이다.
따라서 ArrayList와 달리 명시적으로 Sort() 메서드를 호출할 필요가 없다.
Add() 메서드를 통해 요소가 삽입될 때마다 자동으로 정렬이 수행된다.
정렬 기준
SortedList의 정렬은 Add() 메서드에 전달되는 첫 번째 인자인 Key를 기준으로 수행된다.
- Key → 정렬 기준
- Value → Key에 따라 함께 위치가 결정됨
즉, Value는 직접 정렬되는 것이 아니라 Key의 정렬 순서에 따라 함께 이동한다.
Key 중복 불가
SortedList는 Hashtable과 마찬가지로 Key가 중복될 수 없다.
만약 동일한 Key를 Add() 메서드로 추가할 경우 ArgumentException 예외가 발생한다.
System.Collection.Stack
Stack 타입은 자료구조의 Stack 구조를 그대로 구현한 컬렉션이다.
Stack은 후입선출(LIFO, Last In First Out) 구조를 가진다.
즉, 나중에 들어온 데이터가 먼저 제거되는 방식이다.
따라서 Stack에 먼저 들어간 데이터는 가장 나중에 나오게 된다.

주요 메서드
Stack에서 대표적으로 사용되는 메서드는 다음과 같다.
| Push() | 데이터를 Stack에 추가 |
| Pop() | 가장 마지막에 추가된 데이터를 제거하고 반환 |
| Peek() | 가장 위에 있는 데이터를 제거하지 않고 확인 |
| Count | 현재 요소 개수 |
Stack에 데이터를 추가할 때는 Push 메서드를 사용하고 데이터를 꺼낼 때는 Pop 메서드를 사용한다.
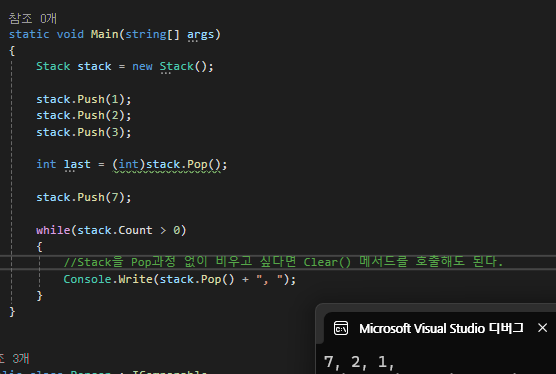
Stack의 Boxing 문제
Stack 타입은 내부적으로 요소를 Object 타입으로 저장한다. 따라서 값 형식(Value Type)을 Stack에 저장할 경우
Object 타입으로 변환되는 Boxing이 발생하게 된다. 또한 데이터를 꺼낼 때는 다시 Unboxing이 발생한다.
이로 인해 성능 저하가 발생할 수 있다.
System.Collections.Queue
Queue 타입은 자료구조의 Queue 구조를 그대로 구현한 컬렉션이고, Queue는 선입선출(FIFO, First In First Out) 구조를 가진다. 즉, 먼저 들어온 데이터가 먼저 제거되는 방식이다.
따라서 Queue에 먼저 추가된 데이터는 가장 먼저 나오게 된다.
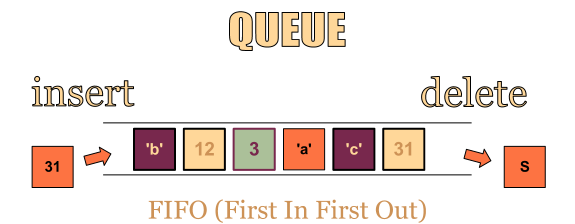
주요 메서드
Queue에서 대표적으로 사용되는 메서드는 다음과 같다.
| Enqueue() | 데이터를 Queue에 추가 |
| Dequeue() | 가장 먼저 추가된 데이터를 제거하고 반환 |
| Peek() | 가장 앞에 있는 데이터를 제거하지 않고 확인 |
| Count | 현재 요소 개수 |

Queue의 Boxing 문제
Queue 타입은 내부적으로 요소를 Object 타입으로 저장한다. 따라서 값 형식(Value Type)을 Queue에 저장할 경우 Object 타입으로 변환되는 Boxing이 발생하게 된다.
또한 데이터를 꺼낼 때는 다시 Unboxing이 발생한다. 이로 인해 불필요한 형 변환이 발생하여 성능 저하의 원인이 될 수 있다.
.NET 초기 컬렉션(ArrayList, Hashtable, Stack, Queue 등)은 Object 기반으로 동작하기 때문에 값 형식을 저장할 경우 Boxing / Unboxing 문제가 발생할 수 있다.
이러한 이유로 현재는 Generic이 적용된 List<T>, Dictionary<TKey, TValue>, Stack<T>, Queue<T> 등의 컬렉션을 사용하는 것이 일반적이다.
Reference
시작하세요! C# 12 프로그래밍 기본 문법부터 실전 예제까지
이미지 출처
[자료구조] - 스택(Stack)의 구조와 구현
1. 스택(Stack)이란? 스택(stack)이란 단어의 사전적인 뜻은, "쌓아놓은 더미"이다. 쌓아놓은 접시들을 생각하면 이해가 쉬울 것이다. 후입선출 (LIFO : Last - In - First - Out) 스택의 중요한 특징이다. 앞
developer-cat.tistory.com
https://donggu1105.tistory.com/163
[자료구조] 큐(Queue) 란? 한번에 쉽고 간단하게 이해하기!
큐(Queue) 란 무엇일까요 ? 큐(Queue)는 한쪽 끝에서만 삽입이 이루어지고, 다른 한쪽 끝에서는 삭제 연산만 이루어지는 유한 순서 리스트이다. 큐(Queue)의 특징 ? First in First Out (FIFO) 선입선출이라고
donggu1105.tistory.com
'C#' 카테고리의 다른 글
| C# BCL(Base Class Library) - 스레딩1 (0) | 2026.03.15 |
|---|---|
| C# BCL(Base Class Library) - 파일 (0) | 2026.03.10 |
| C# BCL(Base Class Library) - 직렬화/역직렬화 (0) | 2026.03.07 |
| C# BCL(Base Class Library) - 문자열 처리 (0) | 2026.03.07 |
| C# BCL(Base Class Library) - 시간 (0) | 2026.03.05 |