프로그램에서 다뤄지는 모든 데이터는 결국 바이트(byte) 형태로 표현된다.
string 타입 역시 C# 소스 코드에서는 겹따옴표(" ")로 감싸진 문자열 형태로 표현되지만, 실제로 파일에 저장되거나 네트워크를 통해 전송될 때는 바이트 데이터 형태로 변환되어 처리된다.
좁은 의미에서 볼 때, 객체나 데이터를 일련의 바이트 배열(byte[])로 변환하는 작업을 직렬화(Serialization) 라고 하며,
이 바이트 데이터를 다시 원래의 데이터 구조로 복원하는 작업을 역직렬화(Deserialization) 라고 한다.
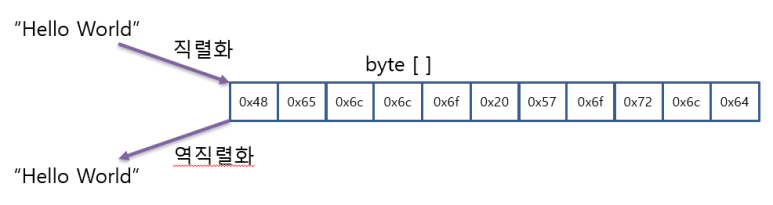
바이트 배열(byte[])은 직렬화를 수행하기 위한 하나의 표현 방식일 뿐이다.
데이터가 특정 저장 매체에 보관될 수 있는 형태로 변환되고, 이후 그 데이터로부터 원래의 데이터를 다시 복원할 수 있다면 이러한 과정을 넓은 의미에서 직렬화(Serialization)와 역직렬화(Deserialization) 라고 볼 수 있다.
System.BitConverter
문자열은 인코딩 방식에 따라 같은 문자열이라도 바이트 배열로의 변환이 달라질 수 있다.
하지만 그 밖의 기본 타입(byte, short, int, ...)은 변환 방법이 고정되어 있다. 그래서 간단하게 BitConverter 타입에서는 GetBytes 메서드를 통해 이런 기능을 제공한다.

이처럼 데이터가 바이트 형태로 표현된 것을 이진 데이터(Binary Data) 라고 한다.
이진 데이터는 결국 0과 1로 이루어진 바이트 단위로 데이터를 표현한 것이다.
ex) bool 타입의 경우 일반적으로 true 값은 바이트 값 1, false 값은 0으로 표현된다.
그런데 short와 int의 바이트 배열 값은 다르다.
ex) 숫자 32,000과 1,652,300값의 2진수와 16진수는 다음과 같다.
32000
->2바이트 2진수: 0111 1101 0000 0000
->2바이트 16진수: 7D 00
1652300
->2진수: 0000 0000 0001 1001 0011 0110 0100 1100
->16진수: 00 19 36 4C
BitConverter를 이용해 숫자를 바이트 배열로 변환하면 바이트의 순서가 예상과 다르게 보일 수 있다.
이는 시스템이 사용하는 엔디언 방식(Endian) 의 차이 때문이다.
엔디언은 여러 바이트로 구성된 데이터를 메모리에 어떤 순서로 저장할 것인지 정의하는 방식이다.
대표적으로 두 가지 방식이 존재한다.
Little Endian
가장 낮은 바이트(LSB, Least Significant Byte) 가 먼저 저장되는 방식이다.
예를 들어 0x12345678 값을 저장하면 메모리에는 다음과 같이 저장된다.
78 56 34 12
현재 대부분의 PC와 x86/x64 시스템은 Little Endian 방식을 사용한다.
Big Endian
가장 높은 바이트(MSB, Most Significant Byte) 가 먼저 저장되는 방식이다.
같은 값을 저장하면 다음과 같이 표현된다.
12 34 56 78
이 방식은 네트워크 프로토콜 등에서 주로 사용되며 Network Byte Order 라고도 불린다.
즉, Little Endian은 낮은 바이트부터 저장하는 방식이고, Big Endian은 높은 바이트부터 저장하는 방식이다.
추가적으로 숫자 데이터는 바이트 배열로 직렬화하는 방법 외에도 문자열 형태로 변환하여 표현하는 방법이 있다.
ex) int 값은 ToString() 메서드를 사용해 문자열로 변환할 수 있다.
이렇게 변환된 문자열은 파일에 저장하거나 네트워크로 전송할 수 있으며, 이후 다시 숫자 값으로 복원할 수 있다.
int n = 1652300;
string text = n.ToString(); //숫자 1652300을 문자열로 직렬화
int result = int.Parse(text); //문자열로부터 숫자를 역직렬화해서 복원숫자 데이터는 바이트 배열 형태의 이진 직렬화뿐만 아니라 문자열 형태의 텍스트 직렬화 방식으로도 표현될 수 있다.
System.IO.MemoryStream
MemoryStream은 Stream 추상 클래스를 상속받은 타입이다.
여기서 Stream 타입은 일련의 바이트 데이터를 읽고 쓰기 위한 공통 기반 클래스로, 다양한 데이터 소스에서 바이트 데이터를 일관된 방식으로 다룰 수 있도록 설계되어 있다.
Stream의 사전적 의미는 "흐름"이며, 프로그래밍에서는 일반적으로 바이트 데이터의 흐름(byte stream) 을 의미한다.
Stream은 데이터를 읽거나 쓰는 작업을 순차적으로 처리하는 것을 기본 정책으로 한다. 즉, 바이트 데이터를 일정한 순서에 따라 읽고 쓰는 방식으로 동작한다.
MemoryStream 타입은 이름 그대로 메모리 공간을 데이터 저장소로 사용하는 Stream 구현체로, 메모리에 바이트 데이터를 순차적으로 읽고 쓰는 작업을 수행한다.
이러한 특성을 이용하면 데이터를 메모리 상에 직렬화하거나, 메모리에 저장된 데이터를 다시 역직렬화하는 작업을 수행할 수 있다.


Stream에서 데이터를 쓰게 되면 내부적으로 유지되는 Position 값이 그만큼 앞으로 이동한다.
Position은 현재 스트림에서 읽거나 쓸 위치를 나타내는 속성이다.

ShortByte 변수에 들어있는 2바이트 데이터가 Write 메서드로 기록되어 Position이 변경되었고 intBytes 변수에 들어 있는 4바이트 데이터를 Write 메서드를 이용해 기록하면, 현재 Position 위치에서부터 순서대로 바이트 데이터가 기록된다. 그리고 기록된 바이트 수만큼 Position 값도 자동으로 증가한다.
이후 Read 메서드를 이용해 데이터를 읽어 역직렬화를 수행할 수 있다. 이때 스트림의 처음부터 데이터를 읽기 위해서는 Position을 0으로 설정해야 한다.
.NET에서 Stream을 상속받은 모든 타입의 기본 동작도 이렇다.
MemoryStream이 내부적으로 유지하고 있는 바이트 배열을 얻기 위해 ToArray 메서드를 호출 할 수 있다.

BitConverter.ToInt32의 두 번째 인자에 2를 지정한 이유는 Stream은 읽을 때마다 자동으로 Position이 이동하므로 항상 0의 값을 주면 되지만, byte 배열에는 Position의 기능이 없으므로 ToInt32 메서드가 취해야 할 바이트의 위치를 직접 알려줘야 한다.
System.IO.StreamWriter / System.IO.StreamReader
Stream에 문자열 데이터를 쓰려면 반드시 Encoding 타입을 이용해 바이트 배열로 변환해야 한다.
MemoryStream stream = new MemoryStream();
byte[] buf = Encoding.UTF8.GetBytes("Hello World");
stream.Write(buf, 0, buf.Length);문자열을 쓸 때마다 매번 이런 식으로 변환을 거쳐야 하는 것은 번거롭기 때문에 마이크로소프트에서는 문자열 데이터를 Stream에 쉽게 쓸 수 있는 용도로 StreamWriter 타입을 BCL에 포함시켰다.
MemoryStream stream = new MemoryStream();
StreamWriter writer = new StreamWriter(stream, Encoding.UTF8);
writer.WriteLine("Hello World");
writer.WriteLine("Anderson");
writer.WriteLine(32000); //문자열 32000 기록
writer.Flush();StreamWriter 타입은 생성자에서 Stream 객체와 문자열 인코딩 방식을 전달받는다.
이후 Write 계열의 메서드가 호출되면 입력된 문자열을 지정된 인코딩 방식에 따라 바이트 배열로 변환한 후 Stream에 기록한다.
만약 Write 메서드의 인자가 문자열이 아닌 경우에도 내부적으로 ToString() 메서드를 호출하여 문자열로 변환한 뒤 동일한 방식으로 처리한다.
내부 버퍼와 Flush()
StreamWriter를 사용할 때는 Flush() 메서드의 동작을 이해하는 것이 중요하다.
StreamWriter는 성능 향상을 위해 내부적으로 바이트 배열 버퍼(buffer) 를 가지고 있다.
짧은 데이터를 Write 메서드로 호출할 때마다 즉시 Stream에 기록하는 것은 비효율적일 수 있기 때문에, StreamWriter는 입력된 문자열을 내부 버퍼에 임시로 저장한다.
그리고 버퍼가 일정 크기에 도달하면 한 번에 Stream으로 쓰기 작업을 수행한다.
Flush() 메서드는 버퍼가 가득 차지 않았더라도 현재 버퍼에 저장된 데이터를 강제로 Stream에 기록하도록 하는 역할을 한다.
따라서 일반적으로 StreamWriter를 사용해 데이터를 모두 작성한 뒤에는 마지막에 Flush()를 호출하여 버퍼에 남아 있는 데이터를 Stream에 기록하도록 한다.
쓰기 작업에 StreamWriter가 있다면, 문자열 읽기 작업에는 StreamReader가 있다.

StreamReader의 두 번째 인자에 지정된 인코딩은 StreamWriter에 지정했던 인코딩과 동일해야 하며, 한 줄씩 읽어들이는 ReadLine 메서드도 있다.
참고로 데이터를 기록할 때 사용한 인코딩 방식과 데이터를 읽을 때 사용하는 인코딩 방식이 서로 다르면 문자 깨짐 현상이 발생할 수 있다.
이는 문자열이 바이트 배열로 변환될 때 사용된 인코딩 규칙과, 바이트 배열을 다시 문자열로 변환할 때 적용되는 인코딩 규칙이 서로 다르기 때문이다.
System.IO.BinaryWriter / System.IO.BinaryReader
BinaryWriter/BinaryReader는 Stream에 2진 데이터를 쓰고 읽는데 특화되어 있다.

StreamWriter와 BinaryWriter의 차이점은 MemoryStream에 기록된 바이트 배열의 내용을 확인해 보면 보다 명확하게 이해할 수 있다.
StreamWriter는 문자열을 지정된 인코딩 방식으로 변환하여 바이트 데이터를 기록하는 반면, BinaryWriter는 기본 자료형의 값을 그대로 이진 형태로 기록한다.
이러한 차이점 때문에 일반적으로 사람이 쉽게 읽을 수 있는 텍스트 데이터를 처리할 때는 StreamWriter와 StreamReader를 사용한다.
반면 데이터의 가독성은 떨어지지만, 미리 정의된 형식의 이진 데이터를 보다 효율적으로 저장하거나 읽어야 하는 경우에는 BinaryWriter와 BinaryReader를 사용한다.
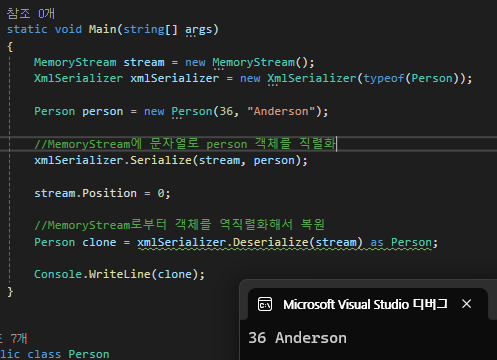
System.Xml.Serialization.XmlSerializer
사용자 정의 클래스의 직렬화
class Person
{
public int Age;
public string Name;
public Person(int age, string name)
{
this.Age = age;
this.Name = name;
}
public override string ToString()
{
return string.Format("{0} {1}", this.Age, this.Name);
}
}XmlSerializer
바이트 배열로 직접 변환하여 Stream에 기록하거나, 객체를 생성한 후 속성 값을 하나씩 대입해 복원하는 방식은 번거롭다.
이를 해결하기 위해 .NET에서는 다양한 직렬화 클래스를 제공한다.
그중 하나가 XmlSerializer 타입이다.
XmlSerializer는 클래스 객체의 데이터를 XML 문자열 형태로 직렬화하고, 다시 객체로 역직렬화할 수 있게 해준다.
즉, 객체를 XML 형식의 데이터로 변환하여 저장하거나 전송할 수 있다.
XmlSerializer의 제약사항
XmlSerializer를 사용하려면 다음 조건을 만족해야 한다.
- public 접근 제한자의 클래스여야 한다.
- 기본 생성자를 포함하고 있어야 한다.
- public 접근 제한자가 적용된 필드만 직렬화/역직렬화 한다.
using System;
using System.Xml.Serialization;
// XmlSerializer 사용을 위한 클래스
// 1. 반드시 public 클래스여야 한다.
public class Person
{
// 2. 기본 생성자(Default Constructor)가 반드시 있어야 한다.
public Person()
{
}
// 3. public 필드 또는 public 속성만 직렬화/역직렬화 된다.
public string Name; // 직렬화 가능
// private 멤버는 직렬화되지 않는다.
private int age; // 직렬화 불가
}
XmlSerializer는 기본적으로 UTF-8 인코딩을 사용하여 객체를 XML 문자열 형태로 직렬화한다.
따라서 MemoryStream에 저장된 내용을 문자열로 변환하면 직렬화된 XML 데이터를 직접 확인할 수 있다.
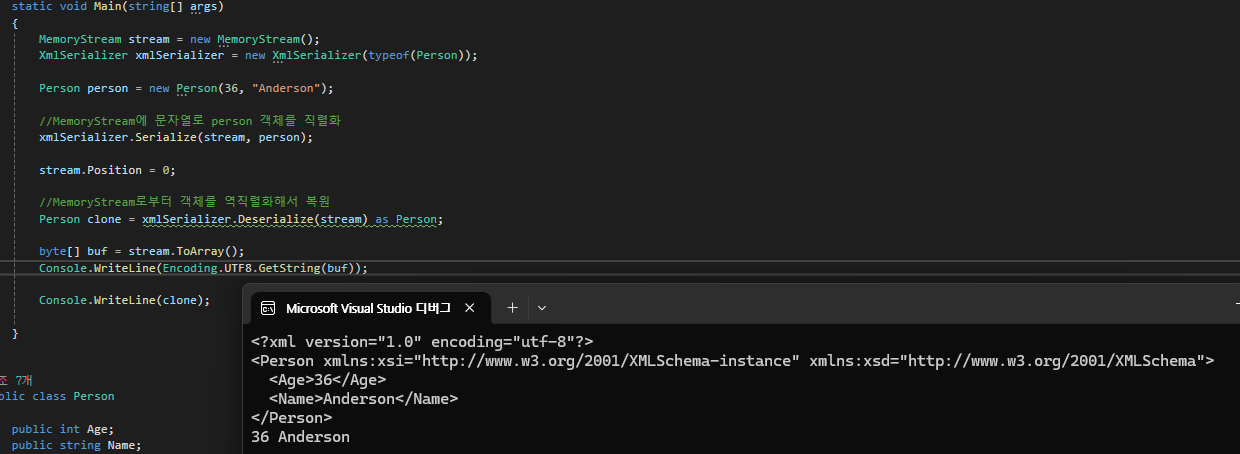
이것은 XmlSerializer의 장점 중 하나로, 직렬화된 데이터를 사람이 쉽게 읽고 이해할 수 있다는 특징이 있다.
출력된 XML을 보면 Person 객체의 Age와 Name 값이 어떤 데이터인지 쉽게 구별할 수 있다.
또한 XML은 플랫폼에 독립적인 데이터 형식이기 때문에, .NET 환경이 아닌 다른 플랫폼의 응용 프로그램과도 데이터를 쉽게 주고받을 수 있다.
예를 들어 다른 시스템에서 XML 데이터를 전달받은 C# 프로그램은 XmlSerializer를 이용해 해당 데이터를 다시 객체로 역직렬화할 수 있다.
이처럼 XML 직렬화는 상호 운용성(Interoperability)이 높은 직렬화 방식이라는 장점이 있다.
하지만 XML은 사람이 읽기 쉬운 텍스트 기반 형식이기 때문에, 데이터를 표현하기 위한 문자열의 크기가 상대적으로 크다는 단점이 있다.
System.Text.Json.JsonSerializer
XmlSerializer는 사용하기 편리하지만, XML 형식으로 데이터를 표현하기 때문에 직렬화된 문자열의 길이가 비교적 길어지는 단점이 있다.
이러한 단점을 보완하기 위해 .NET에서는 System.Text.Json.JsonSerializer 타입을 제공한다.
타입 이름에 포함된 JSON은 JavaScript Object Notation의 약어이다.
JSON은 자바스크립트에서 객체를 표현하기 위해 사용되는 경량 데이터 교환 형식이다.
JsonSerializer는 이러한 JSON 기반 객체 직렬화 방식을 .NET 환경에서 사용할 수 있도록 구현한 클래스이다.
또한 사용 방법도 매우 단순하여, 기존에 XmlSerializer를 사용하던 코드를 JsonSerializer로 비교적 쉽게 변경할 수 있다.
| 구분 | XmlSerializer | JsonSerializer |
| 데이터 형식 | XML | JSON |
| 가독성 | 좋음 | 좋음 |
| 데이터 크기 | 큼 | 비교적 작음 |
| 처리 속도 | 상대적으로 느림 | 더 빠름 |
| 사용 라이브러리 | System.Xml.Serialization | System.Text.Json |
Reference
시작하세요! C# 12 프로그래밍 기본 문법부터 실전 예제까지
직렬화/역직렬화
일련의 바이트 배열로 변환하는 그 작업을 가리켜 직렬화라고 하고, 그 바이트로부터 원래의 데이터를 복원...
blog.naver.com
'C#' 카테고리의 다른 글
| C# BCL(Base Class Library) - 파일 (0) | 2026.03.10 |
|---|---|
| C# BCL(Base Class Library) - 컬렉션 (0) | 2026.03.09 |
| C# BCL(Base Class Library) - 문자열 처리 (0) | 2026.03.07 |
| C# BCL(Base Class Library) - 시간 (0) | 2026.03.05 |
| C# 1.0 - 힙과 스택 (0) | 2025.09.26 |