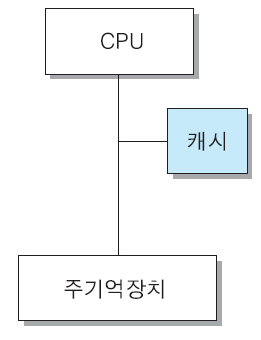
CPU와 주기억장치의 속도 차이로 인한 성능 저하를 방지하기 위한 방법으로서, 대부분의 컴퓨터시스템에서는 CPU와 주기억장치 사이에 고속의 기억장치 칩들을 이용한 소용량의 캐시 메모리를 설치하고 있다.
캐시 메모리(Cache memory)
- CPU와 주기억장치의 속도 차이를 보완하기 위하여 그 사이에 설치하는 반도체 기억장치
- 캐시는 CPU 칩과 인접한 곳에 위치하며, CPU 칩 내부에 포함되기도 한다.
- 명령어와 데이터를 별도의 캐시에 분리하여 저장하며, 여러 레벨의 계층적 캐시로 구성하는 방법도 널리 사용되고 있다.
- 캐시로는 고속의 반도체 기억 장치 칩들을 사용하기 때문에, 캐시 액세스 시간이 주기억자이 액세스 시간보다 짧다.
- 그러나 칩의 가격이 그만큼 더 높아지고 설치할 수 있는 공간도 제한되기 때문에, 캐시의 용량은 일반적으로 주기억장치의 용량에 비해 훨씬 적다.
- CPU가 기억장치로부터 어떤 데이터를 읽으려고 할 때는 먼저 그 데이터가 캐시에 있는 지 검사한다.
- 만약 있다면 데이터를 즉시 CPU로 인출할 수 있기 때문에 액세스 시간이 크게 단축된다.
- 없다면, 그 데이터를 주기억장치로부터 인출해야 하기 떄문에 더 오랜 시간이 걸린다.
주기억장치로부터 인출되어 CPU에 의해 사용되는 데이터는 캐시에도 적재(load)된다. 프로그램 수행이 진행되는 동안에 그러한 과정은 데이터뿐 아니라 명령어들에 대해서도 반복되며, 결과적으로 어느 정도 시간이 경과한 후에는 주기억장치의 내용 중에서 CPU가 한 번 이상 액세스하였던 많은 부분들이 캐시에 복사되있는 상태가 된다.(액세스된 적이 있더라도 캐시의 용량이 적기 때문에 계속 캐시에 남아있지는 못한다.)
CPU가 프로그램 코드나 데이터를 처음으로 액세스할 때는 주기억장치로부터 직접 읽어와야 하지만, 일단 캐시에 적재되어 있는 프로그램 코드나 데이터가 CPU에 의해 다시 사용될 떄는 캐시로부터 신속히 읽어올 수 있다.
- CPU가 원하는 데이터가 이미 캐시에 적재되어 있는 사태를 캐시 적중(cache hit)이라고 한다.
- CPU가 원하는 데이터가 캐시에 없는 상태를 캐시 미스(cache miss)라고 한다.
- 기억장치 액세스들 중에서 캐시에 적중되는 비율을 나타내는 캐시적중률(cache hit ratio) H는 다음과 같이 정의된다.

- 캐시 적중률은 CPU가 원하는 데이터가 캐시에 있을 확률이다.
- 따라서 캐시에 없을 확률인 미스율(miss ratio)은 (1 - H)가 된다.
캐시가 사용되는 시스템에서 평균 기억장치 액세스 시간 Ta는 다음 식을 이용해 계산이 가능하다.
- Ta = H × Tc + (1 - H) × Tm
- TC : 캐시 액세스 시간
- Tm : 주기억장치 액세스 시간
- 주기억장치로부터 인출된 데이터는 일단 캐시에 적재된 다음에 다시 인출되어 CPU로 전송되기 때문에, 그 캐시 인출 시간을 별도로 고려한다면 두번째 항이 (1 - H) x (Tm + Tc)로 표현되어야 한다.
- 그러나 Tm이 Tc에 비하여 상대적으로 큰 값이기 때문에, Tm에 그 시간도 모두 포함된 것으로 간주하여 일반적으로 Ta = H × Tc + (1 - H) × Tm로 표현한다.
- 캐시 미스의 경우에도 적중 여부를 검사하는 시간은 소모되지만, 상대적으로 짧다.
캐시적중률과 평균 기억장치 액세스 시간의 관계

- 캐시의 적중률이 높아질수록 평균 액세스 시간은 캐시의 액세스 시간에 접근하게 된다.
- 캐시 적중률이 높아질수록 캐시사용의 효과가 더 커진다.
- 캐시 적중률은 프로그램과 데이터의 지역성(locality)에 크게 의존한다.
지역성(locality)
CPU가 주기억장치의 특정 위치에 저장되어 있는 명령어들이나 데이터를 빈번히 혹은 집중적으로 액세스하는 현상
- 시간적 지역성(temporal locality)
- 최근에 액세스된 프로그램 코드(명령어)나 데이터가 가까운 미래에 다시 액세스될 가능성이 높아지는 특성을 말한다.
- ex) 반복 루프 프로그램이나 서브루틴들은 반복적으로 호출되며, 공통 변수들도 빈번히 액세스 된다.
- 공간적 지역성(spatial locality)
- 기억장치 내에 서로 인접하여 저장되어 있는 데이터들이 연속적으로 액세스될 가능성이 높아지는 특성을 말한다.
- ex) 표(table)나 배열 데이터들이 저장되어 있는 기억장치 영역은 그들에 대한 연산이 수행되는 동안에 집중적으로 액세스 된다.
- 순차적 지역성(sequential locality)
- 분기(branch)가 발생하지 않는 한, 명령어들은 기억장치에 저장된 순서대로 인출되어 실행된다.
- 일반적인 프로그램에서는 순차적 실행과 비순차적 실행의 비율이 대략 5 : 1 정도인 것으로 알려져 있다.
프로그램이 수행되는 동안에 실제로 이러한 지역성들 때문에 캐시에 적재되어 있는 정보들이 그 후에 CPU에 의해 다시 사용되는 경우가 많다.
캐시의 사용 목적은 평균 기억장치 액세스 시간을 단축하는 것이고, 그것을 위해서는 가능한 적중률을 높여야 한다.
그러나 지역성은 프로그래머의 특성에 따라 달라지기 때문에 한계가 있다. 따라서 캐시 적중률을 높이는 것 외에도 캐시 설계 과정에서 여러가지 사항을 고려해야 한다.
캐시 설계에 있어서의 공통적인 목표들
- 캐시 적중률의 극대화
- CPU가 원하는 정보(명령어 혹은 데이터)가 캐시에 있을 확률을 높여야 한다.
- 캐시 액세스 시간의 최소화
- 캐시 적중 시에 캐시로부터 CPU로 정보를 인출해오는 데 걸리는 시간을 가능한 단축시켜야 한다.
- 캐시 실패에 따른 지연시간의 최소화
- 캐시 미스가 발생한 경우에 주기억장치로부터 캐시로 정보를 읽어오는 데 걸리는 시간을 최소화시켜야 한다.
- 주기억장치와 캐시간의 데이터 일관성 유지 및 그에 따른 오버헤드의 최소화
- CPU가 캐시의 내용을 변경하였을 떄, 주기억장치에 그 내용을 갱신하는 절차 때문에 발생하는 지연 시간을 최소화 시켜야 한다.
캐시 용량
- 캐시의 크기, 즉 용량이 커질수록 적중률이 높아진다.
- 비용도 같은 비율로 상승하기 때문에, 캐시의 용량은 비용과의 상호조정을 통하여 적절히 결정해야 한다.
- 캐시의 용량이 커질수록 주소 해독 및 정보 인출을 위한 주변회로가 더 복잡해지는 문제도 발생한다.
- 캐시 용량은 칩 혹은 주기판(main board)의 공간에 의해서도 제한을 받는다.
- 캐시 적중률을 높이기 위해서는 캐시의 용량을 증가시키는 것이 필요하지만, 그와 같은 문제들 때문에 최적의 캐시 용량을 결정하는 것은 쉬운 일이 아니다.
인출 방식
- 주기억장치로부터 캐시 정보를 인출해오는 방식도 캐시 적중률에 많은 영향을 준다.
요구인출(demand fetch)
- 캐시 미스가 발생한 경우에, CPU가 필요한 정보만 주기억장치로부터 캐시로 인출해오는 방식
선인출(prefetch)
- CPU가 필요한 정보 외에도 그와 인접해 있는 정보들을 함께 캐시로 인출해 오는 방식
- 요구인출 방식은 필요한 정보만 인출해 오는 방법이고, 선인출 방식은 필요한 정보 외에 앞으로 필요할 것으로 예측되는 정보도 미리 인출해오는 방법이다.
- CPU가 원하는 정보를 인출할 때 그 정보와 근접한 위치에 있는 정보들을 함께 인출하여 캐시에 적재한다.
- 이 방식을 사용하는 이유는 인출되는 정보와 인접한 것들이 지역성에 의해 연속적으로 액세스될 가능성이 많아서 캐시 적중률을 높일 수 있기 때문이다.
- 주기억장치를 액세스할 때 함께 인출되는 정보들의 그룹을 블록(block)이라고 부른다. 블록이 더 커지면 더 많은 정보들을 한 번에 읽어올 수 있지만, 인출 시간이 그만큼 더 길어진다.
- 선인출 방식은 지역성이 높은 경우에는 효과가 있지만, 그렇지 않은 경우에는 인출 시간 때문에 오히려 비효율적일 수도 있다.
- 일반적으로 블록의 크기는 2~4단어 정도가 최적인 것으로 알려져 있다.
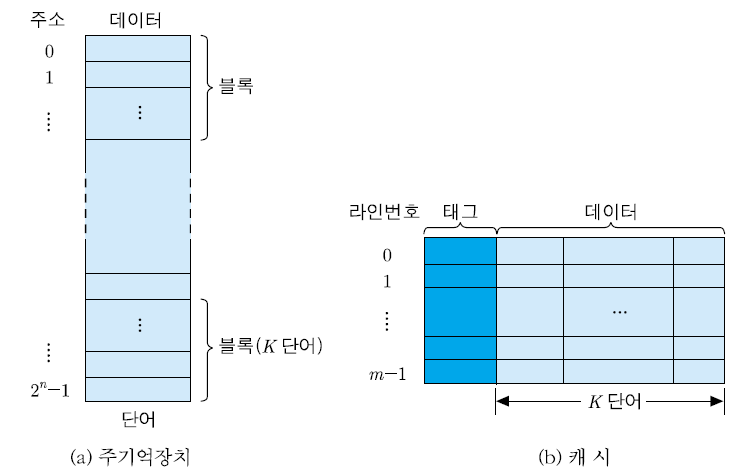
주기억장치는 2^n개의 단어(word)들로 구성되며 각 단어는 n비트의 주소에 의해 지정된다. 선인출을 위하여 주기억장치를 K개의 단어들로 이루어진 블록으로 나눌 경우에 전체 블록의 수는 2^n/K개가 된다.
캐시라인(cache line)
- 주기억장치로부터 캐시로 인출되는 단위인 한 블록(block)이 적재되는 캐시 내 공간
- 캐시는 m개의 라인(line, slot이라고도 부른다.)들로 구성되는데, 각 라인에는 주기억장치 블록과 같은 크기인 K개의 단어들이 저장된다. 따라서 라인의 크기는 주기억장치 블록의 크기와 같아야 한다.
- 선인출 방식을 적용하는 경우에 CPU가 주기억장치로부터 어떤 단어를 읽으면, 그 단어를 포함하고 있는 블록 전체가 캐시 라인들 중의 어느 하나에 적재된다.
- 캐시의 용량이 작기 떄문에 캐시 라인의 수는 주기억장치 블록의 수보다 훨씬 더 적다.
- 어느 순간에든 기억장치 블록들 중의 일부분만이 캐시에 적재될 수 있다.
- 결과적으로, 캐시의 각 라인은 여러 개의 블록들에 의해 공유된다.
- 각 캐시라인에는 데이터 블록 외에도 현재 자신을 공유하는 블록 중의 어느 거싱 적재되어 있는 지를 구분해주는 태그가 저장되어있어야 한다.
태그(tag)
- 캐시 라인을 공유하는 블록 중에서 어느 것이 적재되어 있는지를 가리키는 비트들
사상 방식
- 캐시는 주기억장치보다 용량이 훨씬 더 작기 떄문에 캐시의 라인이 여러 개의 주기억장치 블록들에 의해 공유된다.
- 어떤 주기억장치 블록들이 어느 캐시 라인을 공유할 것인지를 결정해주는 방법이 필요한데. 그 방법을 주기억장치와 캐시 간의 사상 방식(mapping scheme)이라고 하는데, 캐시 적중률에도 많은 영향을 미치는 주요 설계 요소이다.
사상 방식(mappiong scheme)
- 주기억장치 블록이 어느 캐시 라인에 적재될 수 있는지를 결정해주는 알고리즘
- 캐시의 내부 조직은 사상 방식에 의해 결정된다. 가장 널리 사용되고 있는 사상 방식으로는 세 가지가 있는데, 직접 사상(direct mapping), 완전-연관 사상(fully-associative mapping), 세트-연관 사상(set-associative mapping) 방식 등이다.
- 각 방식의 설계 원리와 내부 조직
직접 사상(direct mapping)
- 주 기억장치 블록이 지정된 어느 한 라인에만 적재될 수 있는 사상 방식
- 직접 사상 방식에서 주기억장치의 블록들이 지정된 어느 한 캐시 라인으로만 사상될 수 있는데, 각 블록은 지정된 특정 라인에만 적재될 수 있다는 것이다.
이 방식을 구현하기 위해 주기억장치 주소는 세 개의 필드들로 구성된 것으로 해석된다.

- 이 주소의 상위(t+l) 비트들은 주기억장치 2^t+l개의 블록들 중의 하나를 지정해준다.
- 최하위 w비트들은 2^w개의 단어들로 구성된 각 블록 내의 단어들을 구분하는 데 사용된다. 캐시 제어기(cache controller)는 최상위 t개의 비트들을 태그(tag) 번호로 해석하고, 그 다음 l개의 비트들은 라인 번호로 해석한다.
- 라인 번호는 캐시의 m = 2^l개의 라인들 중에서 그 블록이 적재될 수 있는 라인을 지정해준다.
- 태그 번호는 같은 캐시 라인을 공유하는 주기억장치 블록들을 서로 구분하는데 사용된다.
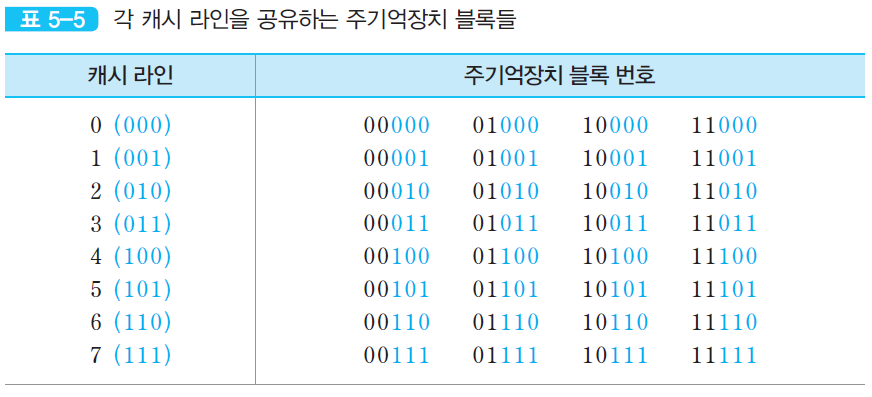
- 이 방식에서 주기억장치의 블록 j가 적재될 수 있는 캐시 라인의 번호 i는 식과 같은 모듈로(modulo) 함수에 의해 결정된다.
- i = j mod m
- ex) 캐시 라인의 수 m = 4라면, 주기억장치의 여섯 번째 블록(j = 6)은 6 mod 4 = 2이므로 캐시의 2번 라인에 적재될 수 있다.

- 각 캐시 라인은 2^t개의 블록들에 의해 공유된다. 따라서 어떤 블록이 지정된 라인에 적재되었을 때, 그 라인을 공유하는 다른 블록들과 구분될 수 있도록 하기 위하여 그 블록에 태그를 붙여야 한다.
- 주기억장치 주소의 태그 필드 비트들이 그 용도로 사용된다.
- 결과적으로, 캐시의 각 라인에는 태그와 데이터 블록이 함께 저장되며, 캐시 적중 여부는 주소의 태그 비트들과 라인에 저장된 태그 비트들을 비교함으로써 결정된다.
직접 사상 방식을 이용한 캐시의 내부 조직

이 조직에서 읽기 동작은 다음과 같이 진행된다.
- 캐시로 기억장치 주소가 보내지면, 그 주소 비트들 중에서 라인 필드의 l비트들에 의해 캐시의 해당 라인이 선택된다.
- 선택된 라인의 태그 비트들이 읽혀져서 주소의 태그 비트들과 비교된다.
- 만약 그 두 태그값이 일치하면, 캐시가 적중된 것이다. 그 경우에는 주소의 최하위에 있는 w개의 비트들을 이용하여 라인 내의 단어들 중에서 하나가 선택되고, 그 단어는 인출되어 CPU로 보내진다.
- 만약 태그 값이 일치하지 않는다면 캐시가 미스 되었다는 것을 의미하므로, 깅거장치 주소 전체가 주기억장치로 보내져서 한 블록을 인출해오게 된다.
- 인출된 블록은 지정된 캐시 라인에 적재되며, 주소의 태그 비트들이 그 라인의 태그 필드에 저장된다.
- 만약 그 라인을 공유하는 다른 블록이 이미 그 라인에 적재되어 있는 상태라면, 원래의 블록은 지워지고 새로이 인출된 블록이 적재된다.
직접 사상 캐시의 예시
- 주기억장치의 용량은 128바이트이다. 따라서 주기억장치의 주소는 7비트이며, 바이트 단위로 주소가 지정된다.
- 단어의 길이는 한 바이트인 것으로 가정한다.
- 주기억장치의 블록 크기를 4단어(즉, 4바이트)로 한다. 따라서 블록의 수는 128/4 = 32개가 된다.
- 캐시의 크기는 32바이트이다.
- 주기억장치의 블록 크기가 4바이트이므로 캐시 라인의 크기도 4바이트가 되어야 하며, 결과적으로 라인의 수 m = 32/4 = 8개가 된다.
기억장치의 주소 형식

- 각 기억장치 블록이 공유하게 될 캐시 라인 번호
- i = j mod 8
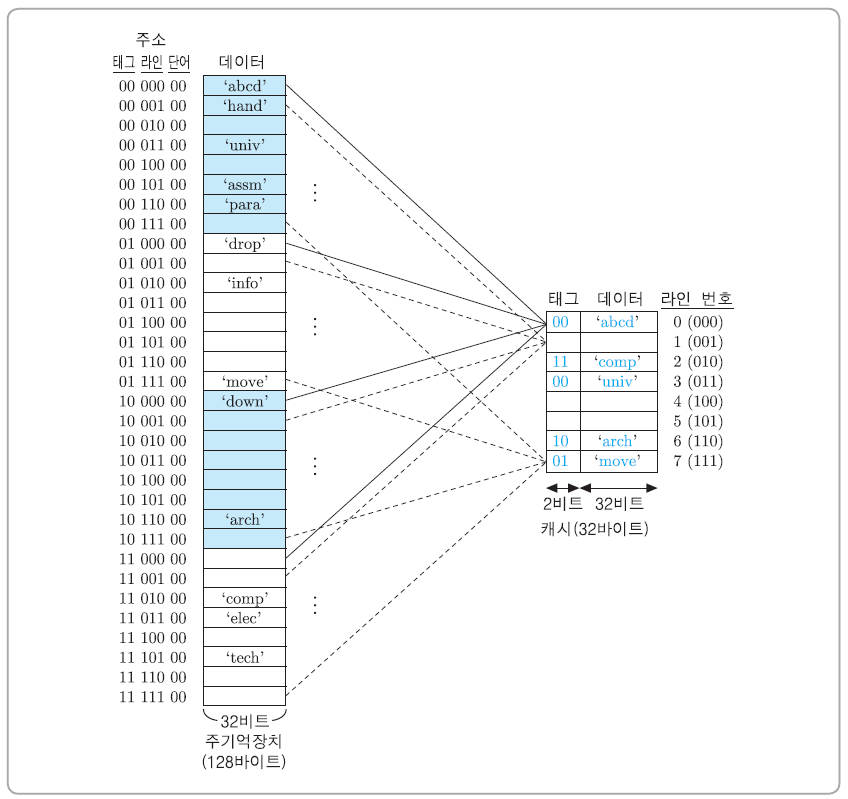
예제 5-2
프로그램 수행 중의 어느 시점에서 직접 사상 캐시의 라인들이 위 이미지처럼 블록들을 적재하고 있다고 가정한다. 이때 CPU로부터 다음과 같은 기억장치 주소들이 발생된 경우에 '캐시 적중'인지 혹은 '캐시 미스'인지를 구분하라. 그리고 캐시 미스인 경우에는 그 블록이 캐시의 해당 라인에 적재된 후의 결과에 대하여 설명하라. 단 주소는 2진수로 표시되어 있다.
(1) 0101000 (2) 0001101
(3) 1110111 (4) 1011010
풀이
- 캐시 미스 : 주소의 태그 비트는 '01'이고, 이 블록이 적재될 수 있는 2번 라인의 현재 태그는 '11'이므로 일치하지 않는다. 따라서 2번 라인의 데이터 필드는 'info'로 대체되고, 태그는 '01'로 변경된다.
- 캐시 적중 : 이 블록은 3번 라인에 적재될 수 있는데, 현재의 태그가 '00'이므로 일치한다.(데이터='univ').
- 캐시 미스 : 이 블록이 적재될 수 있는 5번 라인은 현재 비어있다. 따라서 5번 라인의 데이터 필드에는 'tech'가 적재되고, 태그는 '11'로 세트된다.
- 캐시 적중 : 이 블록은 6번 라인이 적재될 수 있는데, 현재의 태그가 '10'이므로 일치한다.(데이터='arch')
[참고: 단어 필드의 값 이 ’10’이므로, 만약 읽기 동작이라면 ‘arch’ 중에서 세 번째 단어인 ‘c’가 CPU로 읽혀진다.]
직접 사상 방식의 장단점
- 직접 사상 방식은 간단하고, 구현하는 비용이 적게 든다는 장점을 가지고 있다.
- 단점은 각 주기억장치 블록이 적재될 수 있는 캐시 라인이 한 개뿐이라는 점이다. 따라서 만약 어떤 프로그램의 수행 과정에서 같은 라인에 사상되는 두 개의 블록들로부터 데이터들을 번갈아 읽어와야 한다면, 그 블록들은 캐시에서 반복적으로 교체될 것이고, 결과적으로 적중률은 낮아진다.
완전-연관 사상(fully-associative mapping)
- 주기억장치 블록이 캐시의 어느 라인으로든 적재될 수 있는 사상 방식
- 완전-연관 사상 방식은 주기억장치 블록이 캐시의 어떤 라인으로든 적재될 수 있도록 허용함으로써 직접 사상 방식의 단점을 보완하고 있다.
이 방식에서는 캐시 액세스 과정에서 주기억장치 주소가 아래와 같이 태그필드와 단어 필드로만 구성된 것으로 해석된다.

- 직접 사상 캐시의 예에 완전-연관 사상 방식을 적용할 경우의 태그와 단어필드이다.
- 7-비트 길이의 기억장치 주소는 두 개의 필드로 나누어 진 것으로 해석된다.
- 주기억장치의 주소는 5-비트 태그 필드와 2-비트 단어 필드로 구성 된다.

결과적으로, 태그값이 주기억장치 블록 번호와 같아진다.
- 따라서 어떤 블록이 캐시로 적재될 때, 그 주소의 태그 필드의 모든 비트들이 그 라인의 태그부분에 저장되어야 한다.
- 이 방식에서는 주기억장치 블록이 캐시의 어떤 라인에든 적재될 수 있으므로, 캐시 적중 여부를 검사할 때는 캐시의 모든 라인들의 태그들과 주기억장치 주소의 태그 필드 내용을 비교하여 일치하는 것이 있는지 확인해야 한다.
- 만약 일치하는 라인이 있다면 캐시가 적중된 것이므로, 단어 필드의 값을 이용하여 그 라인에 저장되어 있는 단어들 중의 하나를 인출하여 CPU로 전송한다.
- 만약 태그가 일치하는 라인이 없다면, 캐시 미스가 발생한 것이다. 이 경우에는 주소를 주기억장치로 보내어 해당 단어가 포함된 블록을 인출해 온다.
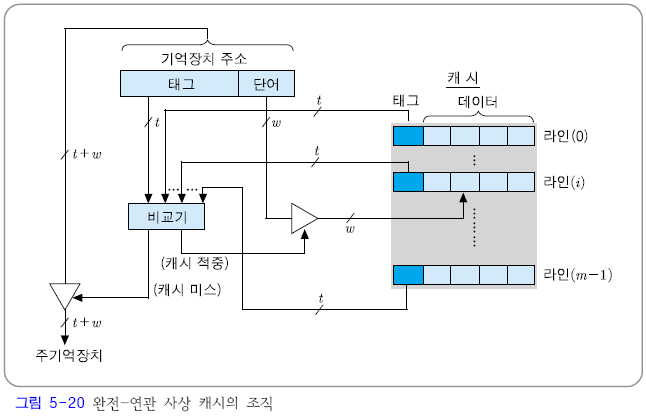
- 기억장치 주소의 태그 비트들은 모든 캐시 라인의 태그들과 비교되어야 한다. 그런데 이 비교를 하나씩 순차적으로 수행하면 많은 시간이 걸릴 것이므로, 연관 기억장치(associative memory) 등을 이용하여 비교 동작이 병렬로 신속히 이루어질 수 있도록 하드웨어가 구성되어야 한다.
- 만약 어떤 라인의 태그값도 일치하지 않는다면, 그것은 캐시 미스를 의미하므로 주기억장치 액세스가 시작된다.
- 그렇지 않다면(캐시가 적중하였다면), 단어 필드의 값을 이용하여 그 라인으로부터 한 단어를 인출하여 CPU로 보낸다.
- 이 방식에서는 주기억장치로부터 인출된 데이터 블록을 캐시의 어느 라인에 적재할 것인지를 결정해야 한다.
- 캐시에 빈 라인들이 있다면, 라인 번호에 따라 차례대로 적재하면 된다.
- 만약 비어있는 라인 없이 캐시가 완전히 채워진 상태일 때 새로운 블록이 인출되어 온다면, 적절한 교체 알고리즘(replacement algorithm)을 이용하여 라인들 중의 하나를 선택한 다음에 새로운 블록을 적재해야 한다.
- 이때 그 라인에 먼저 적재되어 있던 동안에 새로운 내용을 변경된 적이 있었다면, 그 블록을 주기억장치에 갱신(update)한 다음에 새로운 블록을 그 라인에 적재해야 한다.
- 변경된 적이 없다면 그런 과정은 필요하지 않다.
라인들 중에서 교체될 라인을 선택하는 방법은 여러가지가 있다.
ex) 적재된지 가장 오래도니 블록이 저장되어 있는 라인을 선택할 수도 있고, 최근에 액세스된 횟수가 가장 적은 라인을 선택할 수도 있다.

주기억장치 블록들은 비어있는 어느 캐시 라인에든 적재될 수 있으며 5-비트 태그가 캐시의 각 라인에 32-비트 데이터 블록과 함께 저장된다는 것을 확인할 수 있다.
[예제 5-3] 완전-연관 사상 캐시에서의 적중 검사 예
프로그램 수행 중의 어느 시점에서 완전-연관 사상 캐시의 라인들이 위의 그림처럼 블록들을 적재하고 있다고 가정하면, 이때 CPU로부터 다음과 같은 기억장치 주소들이 발생한 경우에 캐시 적중 여부를 확인하라. 그리고 캐시 미스인 경우에는 그 블록이 캐시의 해당 라인에 적재된 후의 결과에 대하여 설명하라.
(1) 1011000 (2) 0010110
(3) 0000001 (4) 0111111
풀이
- 캐시 적중 : 현재 3번 라인에 적재되어 있다.
- 캐시 미스 : 첫 번째 빈 라인인 5번 라인에 적재된다.(태그=00101, 데이터='assm')
- 캐시 미스 : 라인 번호순으로 6번 라인에 적재된다.(xorm=00000, 데이터='abcd')
- 캐시 적중 : 현재 1번 라인에 적재되어 있다.
완전-연관 사상 캐시의 장단점
장점
- 완전-연관 사상에서는 새로운 블록이 캐시로 적재될 때 라인의 선택이 자유롭기 때문에, 프로그램 세그먼트나 데이터 배열 전체가 캐시로 적재될 수도 있다. 이 경우 지역성이 높다면, 적중률이 매우 높아질 것이다.
단점
- 완전-연관 사상 방식은 모든 태그들을 병렬로 검사하기 위하여 복잡하고 비용이 높은 하드웨어를 포함해야 한다는 결정적인 단점이 있기 때문에, 실제 시스템에서는 거의 사용되고 있지 않다.
세트-연관 사상(set-associative mapping)
- 주기억장치 블록이 지정된 어느 한 세트로만 적재될 수 있으며, 각 세트는 두 개 이상의 라인들로 구성된 사상 방식
- 세트-연관 사상 방식은 직접 사상 방식과 완전-연관 사상 방식의 장점만을 취하기 위한 절충안이다.
- 이 경우에 캐시는 먼저 v개의 세트(set)들로 나누어지며, 각 세트는 k개의 라인들로 구성된다.
따라서 전체 캐시 라인의 수 m과 그 변수들 간의 관계는 식 m = v x k와 같아지며,
각 주기억장치 블록이 적재될 수 있는 캐시 세트의 번호 i는 i = j mod v에 의해 결정된다. - 단, i : 캐시 세트의 번호
- j : 주기억장치 블록 번호
- v : 캐시 세트들의 수
직접 사상과 완전-연관 사상의 조합
- 주기억장치 블록 그룹이 하나의 캐시 세트를 공유하며, 그 세트에는 두 개 이상의 라인들이 적재될 수 있다.
- 각 세트에 라인이 두 개가 있는 경우를 2-way 세트-연관 사상이라고 말하며, 네 개가 있는 경우를 4-way 세트-연관 사상이라고 말한다.
- 캐시는 v 개의 세트(set)들로 나누어지며, 각 세트들은 k 개의 라인들로 구성 (k-way 세트-연관 사상 이라고 부름)
- ->세트당 라인이 k개씩 있으면 k-way 세트-연관 사상 이라고 부른다.
기억장치 주소 형식
- 세트-연관 사상을 사용함녀 주기억장치의 블록 Bj는 지정된 세트 i내의 어떤 라인으로든 사상될 수 있다. 이 경우에 캐시 제어 회로는 주기억장치 주소를 다음과 같은 세 개의 필드로 나누어 해석한다.

세트-연관 사상의 동작 원리
- 여기서 s개의 세트 비트들은 캐시의 v = 2^s개 세트들 중에서 해당 주기억장치 블록이 적재될 수 있는 세트를 선택하는 데 사용되고, 태그 필드의 t비트들은 그 세트 내에 있는 라인들의 태그들과 비교되어 캐시 적중 여부를 확인하는 데 사용된다.
- 태그 필드와 세트 필드를 합한 (t+s)비트가 주기억장치의 2(t+s)블록들 중의 하나를 지정
- 그 블록이 적재될 수 있는 세트 번호: 세트 필드에 의해 지정
- 앞의 [예]에 2-way 세트-연관 사상 방식을 적용하는 경우의 주소 형식: (세트 수 = 8/2 = 4개)

- 세트 수 = 캐시 라인 수 (v = m) & 세트 내 라인의 수 k = 1 ➔직접 사상
- 세트 수 = 1 & 세트 내 라인의 수 = 캐시의 전체 라인 수 (k =m) ➔완전-연관사상
2-way 세트-연관 사상 캐시의 조직
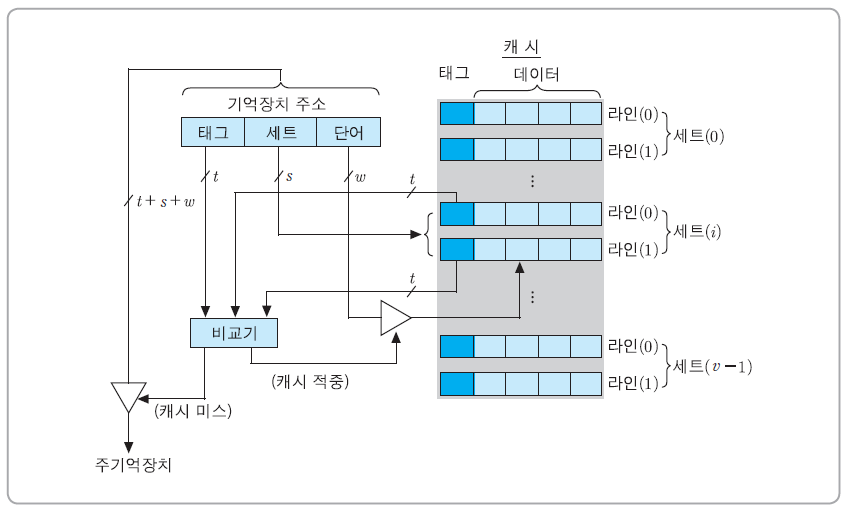
- 캐시의 각 세트가 두 개의 라인들로 구성된 경우, 즉 2-way 세트-연관 사상 캐시의 조직을 보여주고 있다.
- 지정된 세트에 포함된 라인의 태그들이 기억장치 주소의 태그와 비교된다.
- 일치되는 태그가 있다면, 캐시가 적중된 것이므로 w개의 비트에 의해 그 라인 내 2^w개의 단어들 중 하나가 선택되어 인출된다.
- 그 세트 내 어느 라인의 태그와도 일치하지 않는다면, 캐시가 미스된 것이므로 주기억장치 액세스가 시작된다.
- 세트 내 라인들 중의 한 라인에 새로운 블록을 적재 (교체 알고리즘 필요)
2-way 세트-연관 사상 캐시의 예
- [예] 주기억장치 용량 = 128( 27) 바이트
- 블록 크기 = 4 바이트→ 주기억장치 블록 수 = 128/4 = 32 개
- 캐시 크기 = 32 바이트, 라인 크기 = 4바이트, 세트당라인수=2→캐시내세트의수 v=8/2=4개

세트-연관 사상의 예
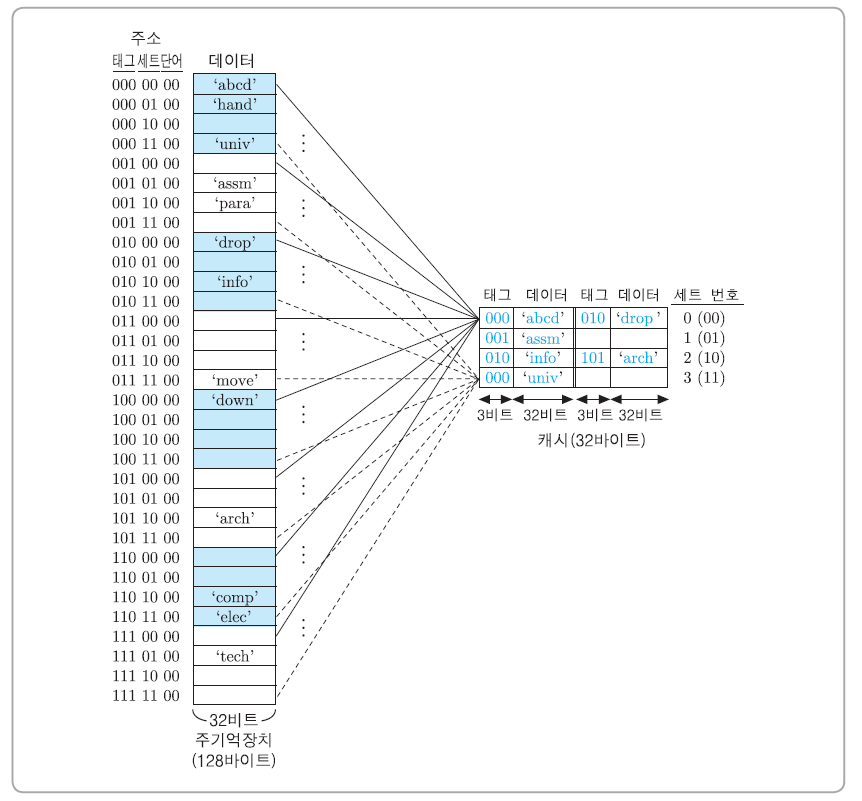
[예제 5-4] 2-way 세트-연관 사상 캐시에서의 적중 검사
프로그램 수행 중의 어느 시점에서 세트-연관 사상 캐시의 라인들이 위의 그림과 같은 블록들을 적재하고 있다고 가정한다. 이때 CPU로부터 다음과 같은 기억장치 주소들이 발생한 경우에 캐시 적중인지 혹은 캐시 미스인지를 구분하라. 단, 주소는 2진수로 표시되어 있다.
(1) 1011010 (2) 1110101
(3) 1000000 (4) 0001111
풀이
- 캐시 적중 : 현재 2번 세트의 두 번째 라인에 적재되어 있다.(태그 = 101, 데이터 = 'arch').
- 캐시 미스 : 이 블록이 적재될 수 있는 1번 세트의 첫 번째 라인의 태그(001)와 주소의 태그 (111)가 일치하지 않는다. 따라서 비어있는 두 번째 라인에 태그 = 111, 데이터 = 'tech'을 저장한다.
- 캐시 미스 : 이 블록이 적재될 수 있는 0번 세트의 두 라인의 태그들(000, 010)이 주소의 태그(100)와 일치하지 않는다. 여기서는 편의상 새로운 블록이 첫 번째 라인에 적재되는 것으로 가정한다면, 그 라인에 태그 = 100, 데이터 = 'down'을 저장한다.
- 캐시 적중 : 현재 3번 세트의 첫 번째 라인에 적재되어 있다.(태그 = 000, 데이터 = 'univ')
큰 용량의 세트-연관 사상 캐시 조직의 예
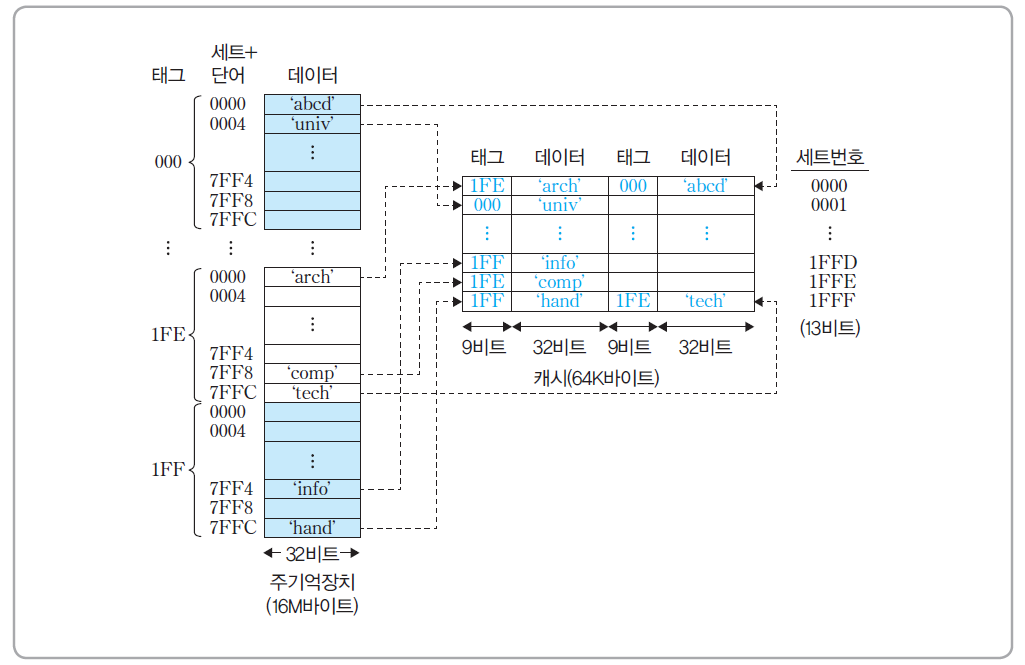
- 주기억장치의 용량은 16M (2^24)바이트이다. 따라서 주기억장치의 주소는 24비트이고, 바이트 단위로 주소가 지정된다.
- 주기억장치는 4-바이트 크기의 블록들 4M (2^22)개로 구성되어 있다. 그리 고 단어의 길이는 한 바이트이다.
- 캐시의 용량은 64K (2^16)바이트이다.
- 주기억장치의 블록 크기가 4바이트이므로, 캐시 라인의 크기도 4바이트가 되며, 결과적으로 라인 수 m = 16K (2^14 )개가 된다.
- 2-way 세트-연관 사상 조직으로 가정한다. 따라서 세트의 수 v = 8K (213 ) 개 이다.
기억장치 주소 형식

- 2-way 세트-연관 사상 방식을 사용한다면 기억장치 주소는 위와 같이 세 개의 필드들로 나누어 진다.
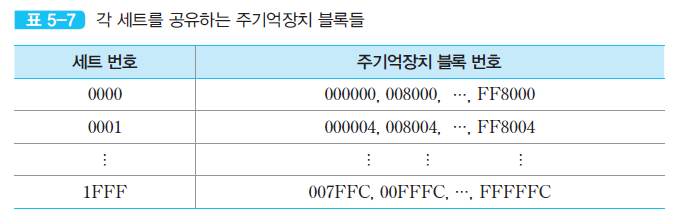
각 세트가 공유하는 주기억장치 블록들
64KByte 크기의 2-way 세트-연관 캐시의 예


Reference
컴퓨터 구조론 개정 5판
https://yz-zone.tistory.com/88
[ 컴퓨터구조 ] 5.5.3 캐시 기억장치 (계속)
큰 용량의 세트-연관 사상 캐시 조직의 예 ▣ 큰 용량의 세트-연관 사상 캐시 조직의 예 ▪ 주기억장치의 용량은 16M (224)바이트이다. 따라서 주기억장치의 주소는 24비트이고, 바이트 단위로 주소
yz-zone.tistory.com
'CS > 컴퓨터 구조론' 카테고리의 다른 글
| 컴퓨터 구조론 5장 [기억장치-DDR SDRAM] (0) | 2025.04.02 |
|---|---|
| 컴퓨터 구조론 5장 [기억장치- 교체 알고리즘, 쓰기 정책, 다중 캐시] (0) | 2025.04.02 |
| 컴퓨터 구조론 5장 [기억장치- 기억장치 모듈] (0) | 2025.03.31 |
| 컴퓨터 구조론 5장 [기억장치- 반도체 기억장치] (0) | 2025.03.31 |
| 컴퓨터 구조론 5장 [기억장치- 계층적 기억장치시스템] (0) | 2025.03.29 |